CAP 定理 (在于数据的一致性)
CAP 定理(CAP Theorem)是由计算机科学家 Eric Brewer 在 2000 年提出的,它指出在分布式系统中,不可能同时满足以下三个特性:
- 一致性(Consistency):
- 所有节点在同一时间看到的数据是一致的。
- 任何读操作都能读到最新的写操作结果。
- 一致性要求:一旦某个数据在分布式系统中的某个节点上被更新(如修改成新值),那么后续对该数据的读取操作,无论发生在哪个节点上,都应该返回更新后的值,即:所有节点在同一时间内,都能看到相同、且最新写入的值。 思考:在
MySQL主从模式下,一个新值写入后还未提交,此时在从节点上读取到了老值,满足CAP的一致性要求吗? 答案是满足,只要保证事务提交前,所有节点读到的数据都为老值,就满足一致性要求!
- 可用性(Availability):
- 系统在任何时候都能响应客户端的请求,返回非错误的结果。
- 即使某些节点发生故障,系统仍然可用。
- 可用性强调的是系统对外部请求的响应能力,具体来说,它要求系统能够在一定的时间内,对任何非失败的外部请求做出响应。这意味着,无论系统内部发生什么情况,只要外部用户发出请求,系统都应该尽快做出响应,即使回应的是拒绝服务或错误消息。因此,可用性关注的是系统对外部请求的响应速度和可靠性。
- 分区容错性(Partition Tolerance):
- 系统在网络分区(即部分节点之间的通信中断)的情况下仍然能够继续运行。
- 分区容错性是分布式系统的基本要求,因为网络分区是不可避免的。
- 节点的加入与断开都可以被认作为系统内的网络分区,因此CAP中的P也可以理解为分布式系统内对于节点动态加入与离开的处理能力
CAP 定理的含义
根据 CAP 定理,分布式系统只能在以下三种组合中选择两种:
- CP 系统:一致性和分区容错性,牺牲可用性。
- AP 系统:可用性和分区容错性,牺牲一致性。
- CA 系统:一致性和可用性,牺牲分区容错性(在实际分布式系统中几乎不可能实现,因为网络分区是不可避免的)。
一致性要求所有节点在同一时间看到相同的数据;
可用性则要求系统能够始终对请求做出响应;
分区容错性则是指系统在遇到网络分区时,仍然能够保持一定的可用性和一致性。
虽然其中的A、P在某些方面看起来相似,但它们关注的焦点并不相同,可用性侧重于系统对用户请求的响应能力,而分区容错性则更侧重于系统在出现网络分区时的表现。假设我们自己要研发一款分布式组件,如果要保证CA(一致性与可用性),该怎么实现?
可用性可以理解成高可用,高可用的前提是解决单点故障,因此我们可以考虑集群设计方案,使用多个节点来组成整个系统,当系统部分节点出现故障时,外部请求能自动转移到其他健康的节点上处理。通过这种方案,我们可以保证系统在节点故障时的可用性,不过这里又有个问题,如何感知节点是否健康?
设计健康检查机制!而最主流的方案则是心跳机制,就好比一个正常的人,一定会有心跳,换到程序设计中,一个正常的节点,必然也具备发送心跳包的能力。反之,如果一个节点发送不了心跳包,或者系统内其他节点收不到某个节点的心跳包,说明该节点已经处于故障状态,后续不用将请求转发到该节点。
保障了可用性后,接着来看看一致性,因为此时有多个节点,多个节点的数据一致该怎么实现?选择2PC、3PC这类强一致方案,当外部往某个节点写入数据时,该节点触发数据同步机制,将写入的数据同步给所有节点,当所有都同步完成后,再给客户端返回写入成功,这样就能保证所有节点数据完全一致。
通过上述步骤,就设计出了一个简易版的CA分布式组件,存在什么问题吗?问题很大,节点间的心跳检测、数据同步,需要依靠网络进行通信,先来看看心跳检测的问题:
某个节点其实很健康,但发出的心跳包,因为网络抖动造成丢包,其他节点没收到就认为它故障了,这合理吗?不合理。
某个节点发出的心跳包,部分节点收到了,部分节点没收到,一部分节点认为健康,一部分节点认为故障,从而造成了分区,怎么办?
再来看看保证一致性的数据同步方案,假设某个节点故障,又或者同步数据时的包丢失,导致系统内多个节点数据不一致,系统为了达成“数据一致态”,会不断触发重试机制,造成外部请求阻塞,一直无法成功写入……
综上,最开始的设计思路,只是我们最理想的状态,但网络其实是个不可控因素,总会由于各种各样的原因造成故障出现。因此,在设计分布式系统时,网络故障带来的分区问题,一定要率先考虑,如果对分区问题没有容错性,代表系统内一个节点出现问题时,会造成整个系统无法正常运行,这也是为什么只有保证AP、CP的分布式组件,没有保证CA的原因。
PS:有没有能保证
CA的组件呢?答案是有,就是单机版本,毕竟只有一个节点,数据写入成功后,就能保证多个外部请求看到的数据都相同;同样,只要这一个节点活着,系统就肯定可用,也是一种“狭义上的可用”。
综上,分布式肯定要保证P,无法保证P的分布式组件,只能被称为“部署在多个节点上的单体系统”,为此,对于CAP那幅图,正确的画法应该是这样的:
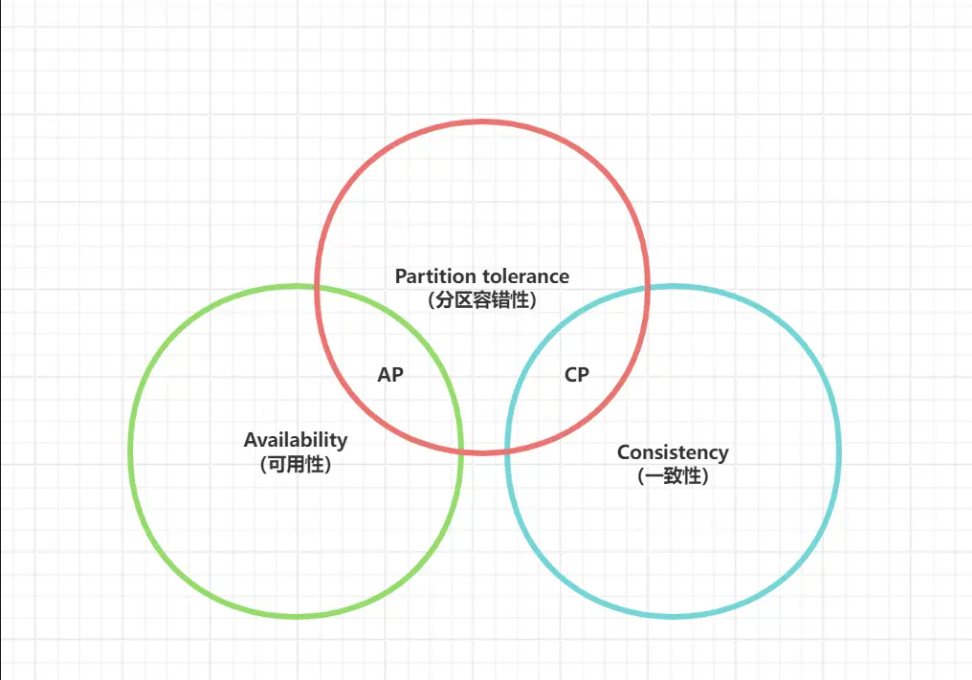
虽然很多人在聊CAP时,说到三选二,可是分布式系统中,实际只能在A、C里选,不存在CA这个组合! 好了,回过头,再来看为什么CAP不能一起实现呢?
分布式系统中的通信离不开网络,而恰恰网络出现故障是常事,在出现分区问题时,节点间的通信会受到严重阻碍,来看个例子:
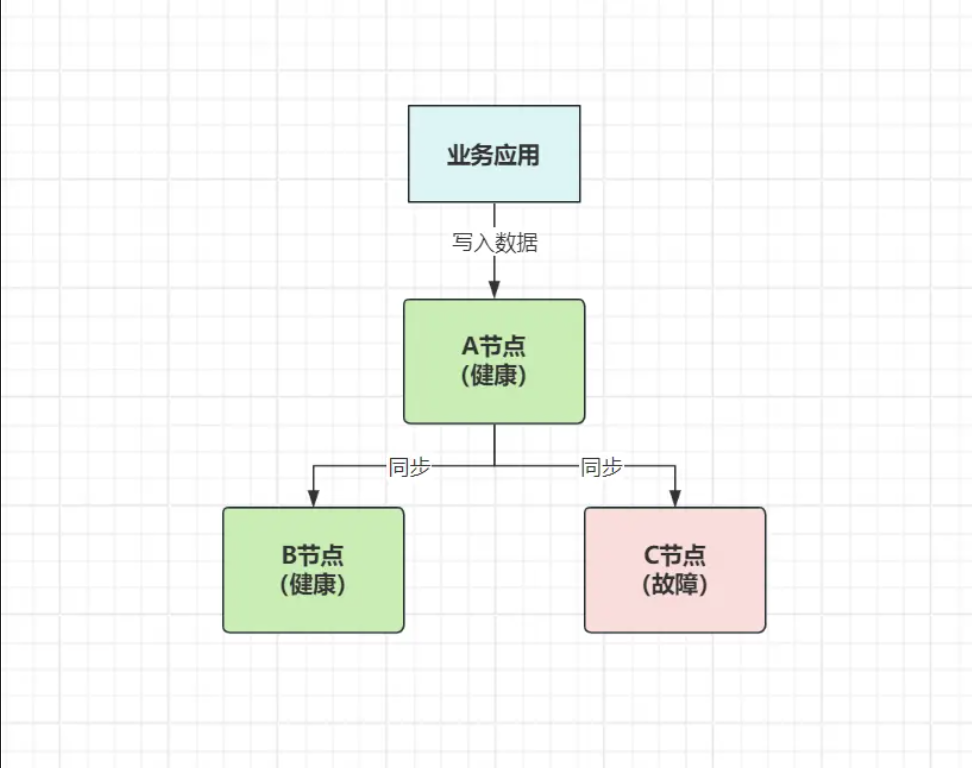
如上图所示,该系统由A、B、C三个节点组成,其中由于C节点故障导致分区问题出现。如果要完全满足CAP里的一致性要求,意味着当外部写入数据时,A节点必须等到C节点同步完成,才能给客户端返回写入成功,可此时C节点已经挂了,注定着数据写不进去……
假设此时出现读取该数据的请求怎么办?此时只有两种办法:
- 放弃可用性:等待所有节点的数据都达到一致状态,保证任意节点返回的数据都相同,可这时系统必然无法及时响应;
- 放弃一致性:给客户端返回已经写入进
A、B的新数据,但后续C节点恢复,请求去到C时,会出现读取到的数据不一致;
通过这个例子,相信大家一定明白了C、A之间为何只能选一个,保证可用性(AP),虽然可以快速响应外部请求,但无法做到任意时间点、所有节点数据的一致;保证一致性(CP),就需要等到所有节点数据达到一致,从而造成系统无法及时响应外部请求,可用性降低。
PRO 原则(为了实现 AP下的HC)
恢复点目标,指在数据库灾难发生之后会丢失多长时间的数据,分布式关系型数据库PRO=0,即不会丢失数据
PRO 原则(Principles of Replicated Data)是分布式数据库设计中的一组原则,旨在指导如何在分布式系统中实现数据复制。PRO 原则包括以下三个方面:
- P(Partition):
- 数据分区(Sharding):将数据分布到不同的节点上,以提高系统的扩展性和性能。
- 分区容错性:确保系统在部分节点故障或网络分区的情况下仍然能够继续运行。
- R(Replication):
- 数据复制:将数据复制到多个节点上,以提高系统的可用性和容错性。
- 复制策略:包括同步复制和异步复制,同步复制保证强一致性,但可能影响性能;异步复制提高性能,但可能导致数据不一致。
- O(Operation):
- 操作一致性:确保在数据复制过程中,操作的一致性。
- 操作顺序:确保操作的顺序在所有节点上是一致的,避免数据冲突。
PTO 原则(为了实现CP下的HA)
恢复时间目标,指在数据库发生灾难后系统恢复到正常使用所需要的时间,分布式关系型数据RTO<几分钟,能快速回到正常使用状态
PTO 原则(Principles of Time Ordering)是分布式系统中用于处理时间顺序的一组原则,旨在确保分布式系统中的事件顺序一致。PTO 原则包括以下三个方面:
- P(Physical Time):
- 物理时间:使用物理时钟(如 NTP 同步时钟)来确保事件的时间顺序。
- 物理时间的局限性:物理时钟可能存在误差,无法完全保证时间顺序的一致性。
- T(Logical Time):
- 逻辑时间:使用逻辑时钟(如 Lamport 时钟、Vector 时钟)来确保事件的时间顺序。
- 逻辑时间的优点:逻辑时钟不受物理时钟误差的影响,能够更好地保证时间顺序的一致性。
- O(Ordering):
- 事件顺序:确保分布式系统中的事件顺序一致。
- 顺序一致性:确保在所有节点上,事件的顺序是一致的,避免数据冲突。
使用CAP视角看目前成熟的分布式方案
Quorum Replication N (副本数) W(写入成功数)R(读取成功副本数) W+R >N ,永远只有一个副本是最新且正确的 N = 3 , W =1 , R=3 (写可用AP,读一致CP) N = 3 , W =3 , R=1 (写一致CP,读可用AP)
 YJ
YJ