多线程与并发
多线程编程是现代软件开发中的一项关键技术,它通过将复杂的任务分解为多个独立的线程并行执行,充分利用多核处理器的优势,从而提高程序的性能和响应能力。然而,多线程编程也带来了诸多挑战,例如线程同步、死锁、竞态条件等问题。本文将从原理层面重新梳理多线程编程的核心概念,并探讨如何优化多线程程序。
程序、进程、线程、协程
提到多线程,大家通常会听到的是进程、线程、协程,那么他们之间又有什么相似之处呢,又有什么区别呢?
可执行程序
- C/C++ 等源文件经过编译器(编译+链接)处理后,生成可执行程序文件。不同系统有不同格式,例如 Linux 的 ELF 格式和 Windows 的 EXE 格式。
- 特点:可执行程序是静态的,存储在磁盘上,包含程序的代码、数据以及操作系统加载和执行程序所需的信息。
逻辑线程:
程序上的线程是一个逻辑上的概念,也叫任务、软线程、逻辑线程,它定义在程序的代码中,线程的执行逻辑由代码描述,它描述了程序的执行逻辑,即“做什么”以及“如何做”。
int sum(int a[], int n) {
int x = 0;
for (int i = 0; i < n; ++i)
x += a[i];
return x;
}这个函数的逻辑很简单,它没有再调用其他函数(更复杂的功能逻辑可以在函数里调用其他函数)。我们可以在一个线程里调用这个函数对某数组求和;也可以把 sum 设置为某线程的入口函数,每个线程都会有一个入口函数,线程从入口函数开始执行。sum 函数描述了逻辑,即要做什么以及怎么做,偏设计;但它没有描述物质,即没有描述这个事情由谁做,事情最终需要派发到实体去完成。
进程是什么
进程是可执行程序在操作系统上的一次执行。进程是一个动态的概念,表示程序正在运行的状态。
特点:
- 同一份可执行文件可以多次执行,产生多个进程。这类似于一个类可以创建多个实例。
- 进程是资源分配的基本单位。操作系统为每个进程分配独立的内存空间、文件描述符、环境变量等资源。
- 进程之间相互隔离,一个进程崩溃不会影响其他进程。
进程是独立的执行实体,拥有独立的地址空间,因此进程间的通信需要通过操作系统提供的机制来实现。例如:
- 管道(Pipe):管道是一种半双工的通信方式,数据只能以字节流单向流动。通常用于父子进程之间的通信。
- 命名管道(FIFO):命名管道是一种特殊的文件,允许无亲缘关系的进程通过文件系统进行通信。
# 创建命名管道
mkfifo my_fifo
# 进程A写入数据
echo "Hello" > my_fifo
# 进程B读取数据
cat my_fifo- 消息队列(Message Queue):消息队列是一种进程间通信的方式,允许进程通过发送和接收数据块来传递数据。
- 共享内存(Shared Memory):多个进程共享同一块内存区域,通过读写共享内存来传递数据,需要使用同步机制例如信号量来避免数据竞争。
- 套接字(Socket):套接字是一种通用的进程间通信机制,支持不同主机之间的通信。
线程是什么
线程是进程内的一个执行流。一个进程可以包含多个线程,这些线程共享进程的资源(如内存、文件描述符等),但每个线程有自己的栈和寄存器状态。
特点:
- 线程是操作系统调度的最小单位。
- 同一进程内的多个线程共享地址空间(代码、全局变量、堆等),但每个线程有独立的栈。
- 线程之间的上下文切换比进程更快,因为线程共享进程的资源。
线程是进程内的执行流,共享进程的地址空间和资源,因此线程之间的通信相对简单,主要通过共享内存来实现。
硬件线程
硬件线程是逻辑线程执行的物质基础,是实际执行指令的物理资源。
芯片设计领域,一个硬件线程通常指为执行指令序列而配套的硬件单元,一个 CPU 可能有多个核心,然后核心还可能支持超线程,1 个核心的 2 个超线程复用一些硬件。从软件的视角来看,无须区分是真正的 Core 和超出来的 VCore,基本上可以认为是 2 个独立的执行单元,每个执行单元是一个逻辑 CPU,从软件的视角看 CPU 只需关注逻辑 CPU。一个软件线程由哪个 CPU/核心去执行,以及何时执行,不归应用程序员管,它由操作系统决定,操作系统中的调度系统负责此项工作。
协程
协程是用户态的多执行流,由用户程序控制调度,而不是由操作系统内核调度。
特点:
- 轻量级:协程的上下文切换成本比线程更低,因为切换完全在用户态完成,无需陷入内核态。
- 协作式调度:协程的调度由程序员显式控制,协程在执行过程中可以主动让出 CPU。
- 高并发:协程适合高并发场景,例如网络编程、异步 IO 等。
Go 语言内置了对协程的支持,称为 Goroutine。Goroutine 的调度由 Go 运行时负责,开发者只需通过 go 关键字即可启动一个 Goroutine。
进程和线程的关系
在 1996 年的一封邮件中,Linus Torvalds 对进程和线程的关系提出了深刻的见解:
- 进程和线程的本质:进程和线程都是执行上下文(Context of Execution, COE),其状态包括:
- CPU 状态(寄存器等)
- MMU 状态(页映射)
- 权限状态(uid、gid 等)
- 通信状态(打开的文件、信号处理器等)
- 传统观念的局限性:传统观念认为线程只包含 CPU 状态,而其他状态来自进程。Linus 认为这种区分是错误的,是一种“愚蠢的自我设限”。
- Linux 内核认为根本没有所谓的进程和线程的概念,只有 COE(Linux 称之为任务),不同的 COE 可以相互共享一些状态,通过此类共享向上构建起进程和线程的概念。
- 从实现来看,Linux 下的线程目前是 LWP 实现,线程就是轻量级进程,所有的线程都当作进程来实现,因此线程和进程都是用 task_struct 来描述的。这一点通过/proc 文件系统也能看出端倪,线程和进程拥有比较平等的地位。对于多线程来说,原本的进程称为主线程,它们在一起组成一个线程组。
线程的概念
在现代的编程领域中,多线程已经成为了一种事实标准,多线程技术在很多程度上改善了程序的性能以及响应能力,使其能够高效的利用系统资源。
那么什么是多线程呢?线程是一个执行上下文,它包含诸多状态数据:每个线程有自己的执行流、调用栈、错误码、信号掩码、私有数据。Linux 内核用任务(Task)表示一个执行流。
执行流
执行流是指一个任务中依次执行的指令序列。每个线程都有自己的执行流,执行流由指令指针寄存器(IP 或 PC)的值的历史记录来表示。执行流的顺序由程序的逻辑控制流决定,但实际的指令执行顺序可能会受到多种因素的影响,例如分支、跳转、编译器优化和处理器乱序执行等。 以下是一个 C 语言函数 calc 的代码及其对应的汇编代码:
int calc(int a, int b, char op) {
int c = 0;
if (op == '+')
c = a + b;
else if (op == '-')
c = a - b;
else if (op == '*')
c = a * b;
else if (op == '/')
c = a / b;
else
printf("invalid operation\n");
return c;
}calc:
push rbp ; 保存基址指针
mov rbp, rsp ; 设置新的基址指针
sub rsp, 16 ; 为局部变量分配栈空间
mov DWORD PTR [rbp-4], edi ; 保存 a (第一个参数)
mov DWORD PTR [rbp-8], esi ; 保存 b (第二个参数)
mov BYTE PTR [rbp-9], dl ; 保存 op (第三个参数)
mov DWORD PTR [rbp-12], 0 ; c = 0
cmp BYTE PTR [rbp-9], '+' ; if (op == '+')
jne .L2 ; 如果不等于 '+',跳转到 .L2
mov eax, DWORD PTR [rbp-4] ; eax = a
add eax, DWORD PTR [rbp-8] ; eax = a + b
mov DWORD PTR [rbp-12], eax ; c = a + b
jmp .L7 ; 跳转到函数结尾
.L2:
cmp BYTE PTR [rbp-9], '-' ; if (op == '-')
jne .L3 ; 如果不等于 '-',跳转到 .L3
mov eax, DWORD PTR [rbp-4] ; eax = a
sub eax, DWORD PTR [rbp-8] ; eax = a - b
mov DWORD PTR [rbp-12], eax ; c = a - b
jmp .L7 ; 跳转到函数结尾
.L3:
cmp BYTE PTR [rbp-9], '*' ; if (op == '*')
jne .L4 ; 如果不等于 '*',跳转到 .L4
mov eax, DWORD PTR [rbp-4] ; eax = a
imul eax, DWORD PTR [rbp-8] ; eax = a * b
mov DWORD PTR [rbp-12], eax ; c = a * b
jmp .L7 ; 跳转到函数结尾
.L4:
cmp BYTE PTR [rbp-9], '/' ; if (op == '/')
jne .L5 ; 如果不等于 '/',跳转到 .L5
mov eax, DWORD PTR [rbp-4] ; eax = a
cdq ; 将 eax 符号扩展到 edx
idiv DWORD PTR [rbp-8] ; eax = a / b
mov DWORD PTR [rbp-12], eax ; c = a / b
jmp .L7 ; 跳转到函数结尾
.L5:
lea rdi, [rip+.LC0] ; 加载字符串地址 "invalid operation\n"
call printf ; 调用 printf 函数
.L7:
mov eax, DWORD PTR [rbp-12] ; eax = c
leave ; 恢复栈帧
ret ; 返回
.LC0:
.string "invalid operation\n" ; 字符串常量calc 函数被编译成汇编指令,一行 C 代码对应一个或多个汇编指令,在一个线程里执行 calc,那么这些机器指令会被依次执行。但是,被执行的指令序列跟代码顺序可能不完全一致,代码中的分支、跳转等语句,以及编译器对指令重排、处理器乱序执行会影响指令的真正执行顺序。
一条线程的生命周期
当一条线程被实际创建之后,系统会分配给这个线程相应的硬件资源,包括线程 ID、程序计数器、寄存器集合、栈空间以及线程控制块(TCB)。线程从指定的入口函数开始执行,入口函数的地址会被压入线程栈中,程序计数器(PC)指向入口函数的第一条指令,线程开始执行执行流。
在执行过程中,当入口函数调用其他函数时,系统会为每个函数调用创建一个栈帧(Stack Frame),并将其压入线程栈中。栈帧中包含了函数的返回地址、局部变量、参数以及临时数据等信息。每个栈帧对应一个函数的执行上下文。当一个函数执行结束时,它的栈帧会从线程栈中弹出,程序计数器会恢复到调用函数的返回地址,继续执行调用函数的后续指令。这个过程会一直持续,直到线程栈中的所有栈帧都被弹出,线程的执行流结束。
可以预见的是,当线程中一个函数包含大量任务之后,线程会因为硬件资源的不足而崩溃或执行缓慢。在现代高复杂度的工程中,将任务交给一个线程去处理是不现实的,因此多线程应运而生。多线程的核心思想是将任务分解为多个子任务,分配给多个线程并发执行,从而提高系统的吞吐量和响应速度。
线程相关概念
时间分片(cpu时间分片)
CPU 先执行线程 A 一段时间,然后再执行线程 B 一段时间,然后再执行线程 A 一段时间,CPU 时间被切分成短的时间片、分给不同线程执行的策略就是 CPU 时间分片。时间分片是对调度策略的一个极度简化,实际上操作系统的调度策略非常精细,要比简单的时间分片复杂的多。如果一秒钟被分成大量的非常短的时间片,比如 100 个 10 毫秒的时间片,10 毫秒对人的感官而言太短了,以致于用户觉察不到延迟,仿佛计算机被该用户的任务所独占(实际上并不是),操作系统通过进程的抽象获得了这种任务独占 CPU 的效果(另一个抽象是进程通过虚拟内存独占存储)。
上下文切换
把当前正在 CPU 上运行的任务迁走,并挑选一个新任务到 CPU 上执行的过程叫调度,任务调度的过程会发生上下文切换(context swap),即保存当前 CPU 上正在运行的线程状态,并恢复将要被执行的线程的状态,这项工作由操作系统完成,需要占用 CPU 时间(sys time)。
线程安全函数与可重入
一个进程可以有多个线程在同时运行,这些线程可能同时执行一个函数,如果多线程并发执行的结果和单线程依次执行的结果是一样的,那么就是线程安全的,反之就不是线程安全的。
不访问共享数据,共享数据包括全局变量、static local 变量、类成员变量,只操作参数、无副作用的函数是线程安全函数,线程安全函数可多线程重入。每个线程有独立的栈,而函数参数保存在寄存器或栈上,局部变量在栈上,所以只操作参数和局部变量的函数被多线程并发调用不存在数据竞争。
C 标准库有很多编程接口都是非线程安全的,比如时间操作/转换相关的接口:ctime()/gmtime()/localtime(),c 标准通过提供带_r 后缀的线程安全版本,比如:
char* ctime_r(const time* clock, char* buf);
这些接口的线程安全版本,一般都需要传递一个额外的 char * buf 参数,这样的话,函数会操作这块 buf,而不是基于 static 共享数据,从而做到符合线程安全的要求。
线程私有数据
因为全局变量(包括模块内的 static 变量)是进程内的所有线程共享的,但有时应用程序设计中需要提供线程私有的全局变量,这个变量仅在函数被执行的线程中有效,但却可以跨多个函数被访问。
比如在程序里可能需要每个线程维护一个链表,而会使用相同的函数来操作这个链表,最简单的方法就是使用同名而不同变量地址的线程相关数据结构。这样的数据结构可以由 Posix 线程库维护,成为线程私有数据 (Thread-specific Data,或称为 TSD)。
Posix 有线程私有数据相关接口,而 C/C++等语言提供 thread_local 关键字,在语言层面直接提供支持。
阻塞和非阻塞
一个线程对应一个执行流,正常情况下,指令序列会被依次执行,计算逻辑会往前推进。但如果因为某种原因,一个线程的执行逻辑不能继续往前走,那么我们就说线程被阻塞住了。就像下班回家,但走到家门口发现没带钥匙,只能在门口徘徊,任由时间流逝,而不能进入房间。
线程阻塞的原因有很多种,比如:
- 线程因为 acquire 某个锁而被操作系统挂起,如果 acquire 睡眠锁失败,线程会让出 CPU,操作系统会调度另一个可运行线程到该 CPU 上执行,被调度走的线程会被加入等待队列,进入睡眠状态。
- 线程调用了某个阻塞系统调用而等待,比如从没有数据到来的套接字上读数据,从空的消息队列里读消息。
- 线程在循环里紧凑的执行测试&设置指令并一直没有成功,虽然线程还在 CPU 上执行,但它只是忙等(相当于白白浪费 CPU),后面的指令没法执行,逻辑同样无法推进。
如果某个系统调用或者编程接口有可能导致线程阻塞,那么便被称之为阻塞系统调用;与之对应的是非阻塞调用,调用非阻塞的函数不会陷入阻塞,如果请求的资源不能得到满足,它会立即返回并通过返回值或错误码报告原因,调用的地方可以选择重试或者返回。
多线程同步
说到多线程同步,可能有人会提出这样的想法:既然线程之间可以通过共享内存的方式共享数据,那么直接将需要共享的变量存到共享内存中不就可以了吗?这种想法看似简单直接,但实际上存在很大的问题。
现代计算机的存储系统并非单一的存储结构,而是由多级存储层次构成,包括寄存器、高速缓存(L1、L2、L3)、主存(RAM)和辅存(如硬盘、SSD)。这些存储层次在速度和成本之间存在显著的权衡:
- 速度:寄存器(1 cycle) > 高速缓存(2 - 20 cycle) > 主存(100 cycle) > 辅存 (1 ms)。
- 成本:寄存器 > 高速缓存 > 主存 > 辅存。 由于速度越快的存储器造价越高,现代计算机采用多级存储层次结构,以在性能和成本之间取得平衡。
正是因为这种多级的存储结构,造成了数据一致性问题 为了方便对于数据一致性问题的讨论,我们先将三级缓存视为一级来考虑。
当一个线程启动之后,系统会分配一定的资源给这个线程,这些资源中包含了cpu及其对应的寄存器,缓存。
| 存储层次 | 访问时间 | 容量 | 特点 |
|---|---|---|---|
| 寄存器 | 1 个时钟周期 | 几十个字节 | 最快的存储单元,用于存储当前处理的数据和指令。 |
| L1 缓存 | 1~4 个时钟周期 | 32KB~64KB | 核心私有,分为指令缓存和数据缓存,访问速度极快。 |
| L2 缓存 | 10~20 个时钟周期 | 256KB~1MB | 核心私有或共享,容量较大,访问速度较快。 |
| L3 缓存 | 20~60 个时钟周期 | 2MB~32MB | 多个核心共享,容量更大,访问速度较慢。 |
| 主存(RAM) | 100~300 个时钟周期 | 几 GB~几十 GB | 主要存储设备,访问速度较慢,是性能瓶颈之一。 |
| SSD | 0.1~0.2 毫秒 | 几百 GB~几 TB | 访问速度比 HDD 快,但比主存慢几个数量级。 |
| HDD | 5~10 毫秒 | 几百 GB~几 TB | 访问速度最慢,受限于机械寻道时间。 |
在现代计算机系统中,CPU 的执行速度非常快,通常每个时钟周期都能处理一条指令(在某些情况下,甚至可以通过流水线和超标量技术同时处理多条指令)。然而,CPU 的速度与存储器的访问速度之间存在巨大的差距。如果 CPU 直接从主存(RAM)中读取指令并执行,假设读取时间为 100 个时钟周期,而执行指令只需要 1 个时钟周期,那么至少有 99 个时钟周期的时间被浪费了,CPU 的资源利用率不到 1%。对于科学家和工程师来说,这种效率是完全不可接受的。
为了更高效地利用 CPU,当线程使用某一片数据时,系统会将该数据及其附近的数据复制到高速缓存(Cache)中,甚至进一步加载到 CPU 寄存器中,以便 CPU 能够快速访问这些数据。
如下图,假设有两个线程(线程 1 和线程 2)同时访问共享变量 A,初始值为 3。线程 1 和线程 2 分别从主存中读取 A 并将其加载到各自的寄存器中。然后,线程 1 将 A 加一变成 4,线程 2 将 A 加二变成 5。最终,当线程 1 和线程 2 将修改后的 A 同步回主存时,由于同步时间未知,主存中的 A 可能被覆盖为 4 或 5,导致数据不一致。 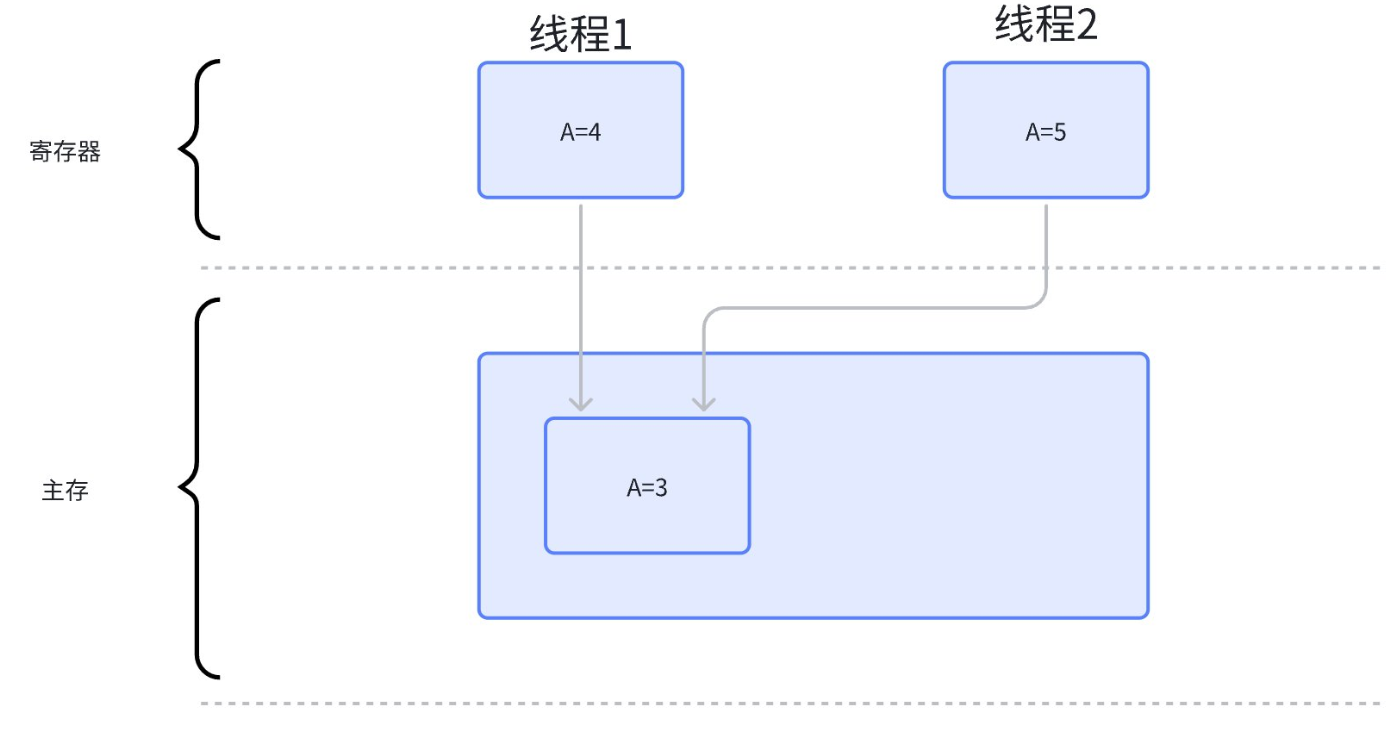
那么为什么会出现这种不一致呢,我们可以观察一下每个线程对这个变量做了什么:
- 线程读取变量A到寄存器
- 线程修改变量A的指
- 线程将寄存器中变量A的值同步到主存中 这三步可以被抽象成“load、update、store”, 可以发现,正是因为在线程 2 在线程 1store 之前就 load 才导致的这种不一致的发生 多线程同步正是为了纠正这种不一致情况的
多线程同步是指:
- 协调多个线程对共享数据的访问,避免出现数据不一致的情况。
- 协调各个事件的发生顺序,使多线程在某个点交汇并按预期步骤往前推进,比如某线程需要等另一个线程完成某项工作才能开展该线程的下一步工作。
在多线程程序里,我们要保护的是数据而非代码,虽然 Java 等语言里有临界代码、sync 方法,但最终要保护的还是代码访问的数据。
原子操作与原子变量
刚刚提到了对于变量自增的步骤可以抽象成“load、update、store”,如果说将这三个步骤合并为一个不可分割的整体,是不是就能解决刚刚发生的不一致的问题了呢?
系统设计师在设计硬件和操作系统时,已经考虑到了这一点,并提供了相应的 API 和硬件支持来实现原子操作。
- 硬件提供了原子指令(如 CAS、Test-and-Set、Fetch-and-Add)来支持原子操作。
- 操作系统和编程语言进一步封装了这些指令,提供了更高级的 API(如原子变量、锁、信号量)。
如何保证原子性是实现层面的问题,应用程序员只需要从逻辑上理解原子性,并能恰当的使用它就行了。
串行化
尽管硬件和操作系统提供了原子操作和原子变量,但在多线程环境中,整个执行流(即一段包含多个指令的代码)通常是非原子性的。这意味着即使单个操作是原子的,多个操作的组合仍然可能导致竞态条件(Race Condition)和数据不一致的问题。
为了解决这个问题,操作系统和并发编程中引入了串行化(Serialization)的概念,即通过某种机制确保多个线程对共享资源的访问是顺序执行的,从而避免冲突。
那么程序员们用了什么样的方法来实现程序的串行化的呢? 这就要谈到锁了
锁
锁是最常见的串行化机制。通过锁,可以确保同一时间只有一个线程可以访问共享资源。 那么什么是锁呢,故名思意,锁可以对一段数据/资源加锁,只有拿到了对应的钥匙之后,才能够访问并修改锁后的资源。
互斥锁
互斥锁可以当作只有一把钥匙的“锁”,当一个线程拿到这把钥匙之后,其它的线程就没有拿到钥匙访问这个资源的机会了
互斥锁有且只有2种状态:
- 已加锁(locked)状态
- 未加锁(unlocked)状态
互斥锁提供加锁和解锁两个接口:
- 加锁(acquire):当互斥锁处于未加锁状态时,则加锁成功(把锁设置为已加锁状态),并返回;当互斥锁处于已加锁状态时,那么试图对它加锁的线程会被阻塞,直到该互斥量被解锁。
- 解锁(release):通过把锁设置为未加锁状态释放锁,其他因为申请加锁而陷入等待的线程,将获得执行机会。如果有多个等待线程,只有一个会获得锁而继续执行。
我们为某个共享资源配置一个互斥锁,使用互斥锁做线程同步,那么所有线程对该资源的访问,都需要遵从“加锁、访问、解锁”的三步: java中提供了很多锁的实现,比较常用的 ReentrantLock() 就提供了 lock() 与 unlock() 方法来实现互斥锁
public class Counter {
private int count = 0;
private Lock lock = new ReentrantLock(); // 创建互斥锁
public void increment() {
lock.lock(); // 加锁
try {
count++;
} finally {
lock.unlock(); // 解锁
}
}
}- 在Counter类中,实例化了一个 ReentrantLock 对象,用于实现互斥锁。
- 在对 count 变量进行访问时,首先需要使用锁的 lock 方法去申请锁,如果能申请成功,那么count++,如果申请失败,线程会陷入阻塞。
- 在方法结束时释放锁。释放锁的操作放在
finally块中,确保即使发生异常,锁也会被正确释放,避免死锁(后面会讲)。
注意:在访问资源前申请锁访问后释放锁,是一个编程契约,通过遵守契约而获得数据一致性的保障,它并非一种硬性的限制,即如果别的线程遵从三步曲,而另一个线程不遵从这种约定,代码能通过编译且程序能运行,但结果可能是错的。
读写锁
互斥锁尽管解决了串行化的问题,但由于每次访问数据都需要申请锁,极大的降低了程序的性能。
想象一下,在一座著名的博物馆里,每天都有成千上万的游客来参观珍贵的展品。同时,博物馆的工作人员也需要定期维护和更新展品,以确保它们保持最佳状态。如果按照互斥锁的方式来约束工作人员与游客的行为,那么在同一时间内只能有一名游客进入场馆参观,这显然是不行的,那么有没有一个方法去重新设计一下这个锁呢? 如果只是工作人员定期维护和更新展品与游客参观互斥,而游客们可以一起来参观博物馆,那么载客量就能大幅度提高,而且不用担心维护和更新时被游客参观到。
由上面这个例子可以看出,读写锁的规则是,读锁共享,写锁互斥。
读写锁有3个状态:
- 已加读锁状态
- 已加写锁状态
- 未加锁状态
对应3个状态,读写锁有3个接口:加读锁,加写锁,解锁:
- 加读锁:如果读写锁处于已加写锁状态,则申请锁的线程阻塞;否则把锁设置为已加读锁状态并成功返回。
- 加写锁:如果读写锁处于未加锁状态,则把锁设置为已加写锁状态并成功返回;否则阻塞。
- 解锁:把锁设置为未加锁状态后返回。
读写锁提升了线程的并行度,可以提升吞吐。它可以让多个读线程同时读共享资源,而写线程访问共享资源的时候,其他线程不能执行,所以,读写锁适合对共享资源访问“读大于写”的场合。读写锁也叫“共享互斥锁”,多个读线程可以并发访问同一资源,这对应共享的概念,而写线程是互斥的,写线程访问资源的时候,其他线程无论读写,都不可以进入临界代码区。
考虑下面这个场景: 如果有线程1、2、3共享资源x,线程1、2不断对x加读锁,因为读锁是可以共享的,所以线程1、2都能顺利运行,这时候线程3想要修改这个资源,对x加了写锁,由于线程1、2的读锁与写锁互斥,线程3一直无法拿到这个资源,被阻塞。
为了避免共享的读线程饿死写线程,通常读写锁的实现,会给写线程优先权,当然这处决于读写锁的实现,作为读写锁的使用方,理解它的语义和使用场景就够了。
自旋锁
尽管读写锁的性能已经很优秀了,但在锁颗粒度较小的时候依旧有优化的空间。 对于上文中的互斥锁、读写锁,线程在没拿到锁的时候需要将线程阻塞挂起,这时候会触发操作系统的上下文切换让出当前线程的cpu资源,而上下文切换是极其消耗系统资源的,如果锁的颗粒度较小,那么进行频繁的上下文会对这段代码的效率有很大的影响。 因此,人们提出了一种不加锁来实现锁功能的锁——自旋锁
自旋锁(Spinlock)的接口跟互斥量差不多,但实现原理不同。线程在acquire自旋锁失败的时候,它不会主动让出CPU从而进入睡眠状态,而是会忙等,它会紧凑的执行测试和设置(Test-And-Set)指令,直到TAS成功,否则就一直占着CPU做TAS。
自旋锁对使用场景有一些期待,它期待acquire自旋锁成功后很快会release锁,线程运行临界区代码的时间很短,访问共享资源的逻辑简单,这样的话,别的acquire自旋锁的线程只需要忙等很短的时间就能获得自旋锁,从而避免被调度走陷入睡眠,它假设自旋的成本比调度的低,它不愿耗费时间在线程调度上(线程调度需要保存和恢复上下文需要耗费CPU)。
内核态线程很容易满足这些条件,因为运行在内核态的中断处理函数里可以通过关闭调度,从而避免CPU被抢占,而且有些内核态线程调用的处理函数不能睡眠,只能使用自旋锁。
而运行在用户态的应用程序,则推荐使用互斥锁等睡眠锁。因为运行在用户态应用程序,虽然很容易满足临界区代码简短,但持有锁时间依然可能很长。在分时共享的多任务系统上、当用户态线程的时间配额耗尽,或者在支持抢占式的系统上、有更高优先级的任务就绪,那么持有自旋锁的线程就会被系统调度走,这样持有锁的过程就有可能很长,而忙等自旋锁的其他线程就会白白消耗CPU资源,这样的话,就跟自旋锁的理念相背。
Linux系统优化过后的mutex实现,在加锁的时候会先做有限次数的自旋,只有有限次自旋失败后,才会进入睡眠让出CPU,所以,实际使用中,它的性能也足够好。此外,自旋锁必须在多CPU或者多Core架构下,试想如果只有一个核,那么它执行自旋逻辑的时候,别的线程没有办法运行,也就没有机会释放锁。
在 Java 中,虽然没有直接提供自旋锁的实现,但可以通过 Atomic 类 和 CAS(Compare-and-Swap) 操作来实现自旋锁的效果。下面是一个简单的自旋锁实现示例。
public class SpinLock {
private AtomicBoolean locked = new AtomicBoolean(false); // 锁状态
// 加锁
public void lock() {
// 忙等待,直到成功获取锁
while (!locked.compareAndSet(false, true)) {
// 自旋等待
}
}
// 解锁
public void unlock() {
locked.set(false); // 释放锁
}
}锁的注意事项
锁的粒度
锁的粒度 是指锁保护的代码范围或资源范围。锁的粒度越小,并发性能通常越好,但代码复杂度也会增加;锁的粒度越大,代码越简单,但并发性能可能会下降。
粗粒度锁
- 锁的粒度较大,保护的范围较广。
- 优点:代码简单,易于实现。
- 缺点:并发性能较差,因为多个线程可能会被阻塞在同一个锁上。
细粒度锁
- 锁的粒度较小,保护的范围较窄。
- 优点:并发性能较好,因为多个线程可以同时访问不同的资源。
- 缺点:代码复杂度较高,需要更精细的设计。
以下是模拟转账系统中粗颗粒度与细颗粒度的实现:
粗颗粒度:用一个全局锁保护所有账户的转账操作
public class Bank {
private final Object lock = new Object(); // 全局锁
public void transfer(Account from, Account to, int amount) {
synchronized (lock) {
if (from.getBalance() >= amount) {
from.debit(amount);
to.credit(amount);
}
}
}
}细颗粒度:为每个账户分配一个锁,只有涉及相同账户的转账操作才会互相阻塞。
public class Bank {
public void transfer(Account from, Account to, int amount) {
// 确保锁的顺序一致,避免死锁
Object firstLock = from.getId() < to.getId() ? from : to;
Object secondLock = from.getId() < to.getId() ? to : from;
synchronized (firstLock) {
synchronized (secondLock) {
if (from.getBalance() >= amount) {
from.debit(amount);
to.credit(amount);
}
}
}
}
}锁的范围
锁的范围 是指锁保护的代码块的大小。锁的范围越小,持有锁的时间越短,其他线程等待锁的时间也就越短,从而提高程序的并发性能。在程序中应尽量减小锁的范围。
死锁
死锁(Deadlock) 是多线程编程中一种常见的并发问题,指的是两个或多个线程互相等待对方释放资源,导致所有线程都无法继续执行的状态。死锁通常发生在多个线程竞争多个资源时。
死锁的发生需要同时满足以下四个条件,缺一不可:
- 互斥条件(Mutual Exclusion):
- 资源一次只能被一个线程占用。
- 占有并等待(Hold and Wait):
- 线程持有至少一个资源,并等待获取其他被占用的资源。
- 不可抢占(No Preemption):
- 线程已持有的资源不能被其他线程强行抢占,必须由线程主动释放。
- 循环等待(Circular Wait):
- 存在一个线程等待的循环链,每个线程都在等待下一个线程所占用的资源。
ABBA型死锁: 假设程序中有2个资源X和Y,分别被锁A和B保护,线程1持有锁A后,想要访问资源Y,而访问资源Y之前需要申请锁B,而如果线程2正持有锁B,并想要访问资源X,为了访问资源X,所以线程2需要申请锁A。线程1和线程2分别持有锁A和B,并都希望申请对方持有的锁,因为线程申请对方持有的锁,得不到满足,所以便会陷入等待,也就没有机会释放自己持有的锁,对方执行流也就没有办法继续前进,导致相持不下,无限互等,进而死锁。 以下是一个经典的死锁示例:两个线程互相等待对方释放锁。
public class DeadlockExample {
private static final Object lock1 = new Object();
private static final Object lock2 = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
synchronized (lock1) {
System.out.println("Thread 1: Holding lock 1...");
try {
Thread.sleep(100); // 模拟耗时操作
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread 1: Waiting for lock 2...");
synchronized (lock2) {
System.out.println("Thread 1: Acquired lock 2!");
}
}
});
Thread t2 = new Thread(() -> {
synchronized (lock2) {
System.out.println("Thread 2: Holding lock 2...");
try {
Thread.sleep(100); // 模拟耗时操作
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Thread 2: Waiting for lock 1...");
synchronized (lock1) {
System.out.println("Thread 2: Acquired lock 1!");
}
}
});
t1.start();
t2.start();
}
}线程1先获取 lock1,然后尝试获取 lock2 线程2先获取 lock2,然后尝试获取 lock1 死锁发生: 线程 1 持有 lock1,等待 lock2。 线程 2 持有 lock2,等待 lock1。 两个线程互相等待,导致死锁。
自死锁(Self-Deadlock): 对于不支持重复加锁的锁,如果线程持有某个锁,而后又再次申请锁,因为该锁已经被自己持有,再次申请锁必然得不到满足,从而导致死锁。
public class SelfDeadlockExample {
private final Object lock = new Object();
public void doSomething() {
synchronized (lock) {
System.out.println("First lock acquired.");
doSomethingElse();
}
}
public void doSomethingElse() {
synchronized (lock) {
System.out.println("Second lock acquired.");
}
}
public static void main(String[] args) {
SelfDeadlockExample example = new SelfDeadlockExample();
example.doSomething();
}
}条件变量(Condition Variable)
条件变量(Condition Variable) 是一种线程同步机制,用于在多线程环境中实现线程间的协调和通信。它的主要作用是让线程在某个条件不满足时进入等待状态,直到其他线程修改了条件并通知它继续执行。
条件变量通常与锁(如 ReentrantLock)配合使用,主要提供以下功能:
- 等待(Wait):
- 线程在条件不满足时,释放锁并进入等待状态。
- 通知(Signal):
- 当条件满足时,通知等待的线程继续执行。
- 唤醒所有等待线程(Broadcast):
- 唤醒所有等待的线程。
假设你要编写一个网络处理程序,I/O线程从套接字接收字节流,反序列化后产生一个个消息(自定义协议),然后投递到一个消息队列,一组工作线程负责从消息队列取出并处理消息。这是典型的生产者-消费者模式,I/O线程生产消息(往队列put),Work线程消费消息(从队列get),I/O线程和Work线程并发访问消息队列,显然,消息队列是竞争资源,需要同步。 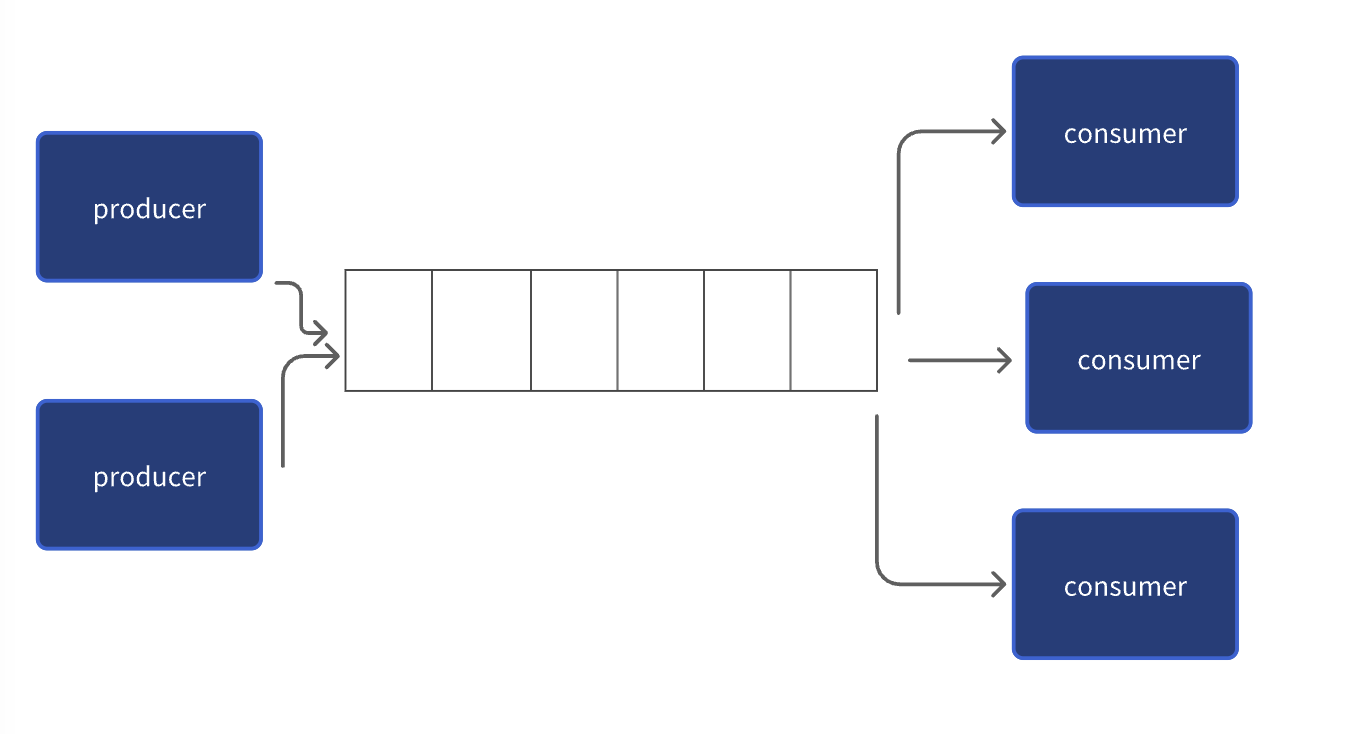
如下是一个java中生产者-消费者的实现:
import java.util.LinkedList;
import java.util.Queue;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class ProducerConsumerExample {
private final Queue<Msg> msgQueue = new LinkedList<>(); // 消息队列
private final int capacity = 10; // 队列容量
private final Lock lock = new ReentrantLock(); // 互斥锁
private final Condition producerCondition = lock.newCondition(); // 生产者条件
private final Condition consumerCondition = lock.newCondition(); // 消费者条件
// 生产者线程
public void ioThread() {
int count = 0;
while (true) {
lock.lock();
try {
// 如果队列已满,等待
while (msgQueue.size() == capacity) {
producerCondition.await();
}
// 生产消息
Msg msg = new Msg("Message-" + count++);
msgQueue.offer(msg);
System.out.println("Produced: " + msg.content);
// 通知消费者
consumerCondition.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
// 模拟生产时间
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
// 消费者线程
public void workThread() {
while (true) {
lock.lock();
try {
// 如果队列为空,等待
while (msgQueue.isEmpty()) {
consumerCondition.await();
}
// 消费消息
Msg msg = msgQueue.poll();
System.out.println("Consumed: " + msg.content);
// 通知生产者
producerCondition.signal();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
// 模拟消费时间
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
// 消息类
private static class Msg {
String content;
Msg(String content) {
this.content = content;
}
}
public static void main(String[] args) {
ProducerConsumerExample example = new ProducerConsumerExample();
// 生产者线程
Thread producer = new Thread(example::ioThread);
producer.start();
// 消费者线程
Thread consumer = new Thread(example::workThread);
consumer.start();
}
}producerCondition:- 当队列已满时,生产者线程调用
producerCondition.await()进入等待状态。 - 当消费者消费数据后,调用
producerCondition.signal()唤醒生产者线程。
- 当队列已满时,生产者线程调用
consumerCondition:- 当队列为空时,消费者线程调用
consumerCondition.await()进入等待状态。 - 当生产者生产数据后,调用
consumerCondition.signal()唤醒消费者线程。
- 当队列为空时,消费者线程调用
条件变量提供了一种类似通知notify的机制,它让两类线程能够在一个点交汇。条件变量能够让线程等待某个条件发生,条件本身受互斥锁保护,因此条件变量必须搭配互斥锁使用,锁保护条件,线程在改变条件前先获得锁,然后改变条件状态,再解锁,最后发出通知,等待条件的睡眠中的线程在被唤醒前,必须先获得锁,再判断条件状态,如果条件不成立,则继续转入睡眠并释放锁。
Lock-free和无锁数据结构
线程同步分为阻塞型同步和非阻塞型同步。
- 互斥量、信号、条件变量这些系统提供的机制都属于阻塞型同步,在争用资源的时候,会导致调用线程阻塞。
- 非阻塞型同步是指在无锁的情况下,通过某种算法和技术手段实现不用阻塞而同步。
锁是阻塞同步机制,阻塞同步机制的缺陷是可能挂起你的程序,如果持有锁的线程崩溃或者hang住,则锁永远得不到释放,而其他线程则将陷入无限等待;另外,它也可能导致优先级倒转等问题。所以,我们需要lock-free这类非阻塞的同步机制。
Lock-free 是一种并发编程的技术,它的核心思想是通过原子操作(atomic operations)来实现线程间的同步,而不需要使用传统的锁(如 mutex 或 semaphore)。Lock-free 的目标是确保系统整体的吞吐量,即使某些线程可能会“饿死”(即长时间无法执行),但至少有一个线程能够持续取得进展。
我们先看一下wiki对Lock-free的描述:
Lock-freedom allows individual threads to starve but guarantees system-wide throughput. An algorithm is lock-free if, when the program threads are run for a sufficiently long time, at least one of the threads makes progress (for some sensible definition of progress). All wait-free algorithms are lock-free. In particular, if one thread is suspended, then a lock-free algorithm guarantees that the remaining threads can still make progress. Hence, if two threads can contend for the same mutex lock or spinlock, then the algorithm is not lock-free. (If we suspend one thread that holds the lock, then the second thread will block.) 翻译: 第1段:lock-free允许单个线程饥饿但保证系统级吞吐。如果一个程序线程执行足够长的时间,那么至少一个线程会往前推进,那么这个算法就是lock-free的。 即:多个线程在时间线上,至少有一个线程处于running状态。 第2段:尤其是,如果一个线程被暂停,lock-free算法保证其他线程依然能够往前推进。
在 Java 中,Lock-free 编程通常依赖于 java.util.concurrent.atomic 包中的原子类(如 AtomicInteger、AtomicReference 等)以及 CAS(Compare-and-Swap)操作来实现。Java 的原子类提供了高效的、无锁的线程安全操作。
原子类
AtomicInteger:原子整型。AtomicLong:原子长整型。AtomicReference<V>:原子引用类型。AtomicBoolean:原子布尔类型。AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray<E>:原子数组类型。
CAS(Compare-and-Swap)是 Lock-free 编程的核心操作。 CAS接受3个参数
- 内存地址
- 期望值,通常传第一个参数所指内存地址中的旧值
- 新值 CAS比较内存地址中的值和期望值,如果不相同就返回失败,如果相同就将新值写入内存
Java 的原子类提供了 CAS 操作的实现,例如:
compareAndSet(expectedValue, newValue):- 如果当前值等于
expectedValue,则将其更新为newValue,并返回true。 - 否则,返回
false。
- 如果当前值等于
下面是java中使用Lock-free技术实现的计数器
import java.util.concurrent.atomic.AtomicInteger;
public class LockFreeCounter {
private final AtomicInteger counter = new AtomicInteger(0);
// 自增操作
public void increment() {
int oldValue;
int newValue;
do {
oldValue = counter.get(); // 读取当前值
newValue = oldValue + 1; // 计算新值
} while (!counter.compareAndSet(oldValue, newValue)); // CAS 操作
}
// 获取当前值
public int getValue() {
return counter.get();
}
public static void main(String[] args) throws InterruptedException {
LockFreeCounter counter = new LockFreeCounter();
// 创建多个线程并发增加计数器
Runnable task = () -> {
for (int i = 0; i < 10000; i++) {
counter.increment();
}
};
Thread t1 = new Thread(task);
Thread t2 = new Thread(task);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("Final value: " + counter.getValue());
}
}使用 AtomicInteger 实现原子操作。 CAS 操作:
compareAndSet(oldValue, newValue) 是一个原子操作,如果当前值等于 oldValue,则将其更新为 newValue。 如果 CAS 失败(说明其他线程已经修改了值),则重试。
以下是一个使用 AtomicReference 实现的 Lock-free 栈:
import java.util.concurrent.atomic.AtomicReference;
public class LockFreeStack<T> {
private static class Node<T> {
final T value;
Node<T> next;
Node(T value) {
this.value = value;
}
}
private final AtomicReference<Node<T>> top = new AtomicReference<>();
// 入栈
public void push(T value) {
Node<T> newNode = new Node<>(value);
Node<T> oldTop;
do {
oldTop = top.get(); // 读取当前栈顶
newNode.next = oldTop; // 新节点的 next 指向旧栈顶
} while (!top.compareAndSet(oldTop, newNode)); // CAS 操作
}
// 出栈
public T pop() {
Node<T> oldTop;
Node<T> newTop;
do {
oldTop = top.get(); // 读取当前栈顶
if (oldTop == null) {
return null; // 栈为空
}
newTop = oldTop.next; // 新栈顶为旧栈顶的 next
} while (!top.compareAndSet(oldTop, newTop)); // CAS 操作
return oldTop.value;
}
public static void main(String[] args) throws InterruptedException {
LockFreeStack<Integer> stack = new LockFreeStack<>();
// 生产者线程
Thread producer = new Thread(() -> {
for (int i = 0; i < 10; i++) {
stack.push(i);
System.out.println("Pushed: " + i);
}
});
// 消费者线程
Thread consumer = new Thread(() -> {
for (int i = 0; i < 10; i++) {
Integer value = stack.pop();
if (value != null) {
System.out.println("Popped: " + value);
}
}
});
producer.start();
consumer.start();
producer.join();
consumer.join();
}
}Node 类: 栈的节点,包含值和指向下一个节点的引用。 AtomicReference<Node<>> 使用 AtomicReference 实现栈顶的原子操作。 CAS 操作 在 push 和 pop 方法中,使用 CAS 操作更新栈顶。
由于Lock-free通过CAS来实现而不是通过锁来实现,而CAS 操作只能检查当前值是否等于预期值,因此它不知道线程的执行顺序(无法检测到值的变化历史),在CAS中会遇到ABA问题(即值从 A 变为 B 又变回 A,CAS 无法检测到中间的变化)。
ABA 问题可能会导致以下问题:
- 数据不一致: 如果程序逻辑依赖于值的变化历史,ABA 问题可能导致数据不一致。
- 逻辑错误: 在某些数据结构(如链表、栈)中,ABA 问题可能导致逻辑错误。
ABA问题可以通过版本号来解决,通过为共享变量添加一个版本号,每次修改值时同时更新版本号。CAS 操作不仅比较值,还比较版本号。
在 CAS 操作中,同时检查值和版本号:
if (currentValue == expectedValue && currentVersion == expectedVersion) {
// 更新值和版本号
}Java 提供了 AtomicStampedReference 类,专门用于解决 ABA 问题。它通过一个整型的“标记”(stamp)来记录值的变化历史。
import java.util.concurrent.atomic.AtomicStampedReference;
public class ABAProblemSolution {
private static final AtomicStampedReference<String> atomicRef =
new AtomicStampedReference<>("A", 0); // 初始值为 "A",版本号为 0
public static void main(String[] args) {
// 线程 1:尝试将 "A" 改为 "B"
new Thread(() -> {
int[] stampHolder = new int[1];
String value = atomicRef.get(stampHolder); // 获取当前值和版本号
if (value.equals("A")) {
boolean success = atomicRef.compareAndSet("A", "B", stampHolder[0], stampHolder[0] + 1);
System.out.println("Thread 1: CAS success? " + success);
}
}).start();
// 线程 2:将 "A" 改为 "B",再改回 "A"
new Thread(() -> {
int[] stampHolder = new int[1];
String value = atomicRef.get(stampHolder);
if (value.equals("A")) {
atomicRef.compareAndSet("A", "B", stampHolder[0], stampHolder[0] + 1);
System.out.println("Thread 2: Changed A -> B");
}
value = atomicRef.get(stampHolder);
if (value.equals("B")) {
atomicRef.compareAndSet("B", "A", stampHolder[0], stampHolder[0] + 1);
System.out.println("Thread 2: Changed B -> A");
}
}).start();
}
}AtomicMarkableReference 是 AtomicStampedReference 的简化版本,它使用一个布尔值作为标记,而不是整型的版本号。
import java.util.concurrent.atomic.AtomicMarkableReference;
public class ABAProblemSolution {
private static final AtomicMarkableReference<String> atomicRef =
new AtomicMarkableReference<>("A", false); // 初始值为 "A",标记为 false
public static void main(String[] args) {
// 线程 1:尝试将 "A" 改为 "B"
new Thread(() -> {
boolean[] markHolder = new boolean[1];
String value = atomicRef.get(markHolder); // 获取当前值和标记
if (value.equals("A")) {
boolean success = atomicRef.compareAndSet("A", "B", markHolder[0], !markHolder[0]);
System.out.println("Thread 1: CAS success? " + success);
}
}).start();
// 线程 2:将 "A" 改为 "B",再改回 "A"
new Thread(() -> {
boolean[] markHolder = new boolean[1];
String value = atomicRef.get(markHolder);
if (value.equals("A")) {
atomicRef.compareAndSet("A", "B", markHolder[0], !markHolder[0]);
System.out.println("Thread 2: Changed A -> B");
}
value = atomicRef.get(markHolder);
if (value.equals("B")) {
atomicRef.compareAndSet("B", "A", markHolder[0], !markHolder[0]);
System.out.println("Thread 2: Changed B -> A");
}
}).start();
}
}代码顺序
程序序:Program Order
顾名思义,即大家写代码时写的程序的顺序
a = 1;
b = 2;按照代码的顺序执行会先执行a=1再执行b=2,从程序角度看到的代码行依次执行叫程序序。
内存序:Memory Order
与程序序相对应的内存序,是指从某个角度观察到的对于内存的读和写所真正发生的顺序。内存操作顺序并不唯一,在一个包含core0和core1的CPU中,core0和core1有着各自的内存操作顺序,这两个内存操作顺序不一定相同。从包含多个Core的CPU的视角看到的全局内存操作顺序跟单core视角看到的内存操作顺序亦不同,而这种不同,对于有些程序逻辑而言,是不可接受的,例如:
程序序要求a = 1在b = 2之前执行,但内存操作顺序可能并非如此,对a赋值1并不确保发生在对b赋值2之前,这是因为:
- 如果编译器认为对b赋值没有依赖对a赋值,那它完全可能在编译期调整编译后的汇编指令顺序。
- 即使编译器不做调整,到了执行期,也有可能对b的赋值先于对a赋值执行。
虽然对一个Core而言,如上所述,这个Core观察到的内存操作顺序不一定符合程序序,但内存操作序和程序序必定产生相同的结果,无论在单Core上对a、b的赋值哪个先发生,结果上都是a被赋值为1、b被赋值为2,如果单核上乱序执行会影响结果,那编译器的指令重排和CPU乱序执行便不会发生,硬件会提供这项保证。
但多核系统,硬件不提供这样的保证,多线程程序中,每个线程所工作的Core观察到的不同内存操作序,以及这些顺序与全局内存序的差异,常常导致多线程同步失败,所以,需要有同步机制确保内存序与程序序的一致,内存屏障(Memory Barrier)的引入,就是为了解决这个问题,它让不同的Core之间,以及Core与全局内存序达成一致。
乱序执行:Out-of-order Execution
乱序执行会引起内存顺序跟程序顺序不同,乱序执行的原因是多方面的,比如编译器指令重排、超标量指令流水线、预测执行、Cache-Miss等。内存操作顺序无法精确匹配程序顺序,这有可能带来混乱,既然有副作用,那为什么还需要乱序执行呢?答案是为了性能。
我们先看看没有乱序执行之前,早期的有序处理器(In-order Processors)是怎么处理指令的?
- 指令获取,从代码节内存区域加载指令到I-Cache
- 译码
- 如果指令操作数可用(例如操作数位于寄存器中),则分发指令到对应功能模块中;如果操作数不可用,通常是需要从内存加载,则处理器会stall,一直等到它们就绪,直到数据被加载到Cache或拷贝进寄存器
- 指令被功能单元执行
- 功能单元将结果写回寄存器或内存位置
乱序处理器(Out-of-order Processors)又是怎么处理指令的呢?
- 指令获取,从代码节内存区域加载指令到I-Cache
- 译码
- 分发指令到指令队列
- 指令在指令队列中等待,一旦操作数就绪,指令就离开指令队列,那怕它之前的指令未被执行(乱序)
- 指令被派往功能单元并被执行
- 执行结果放入队列(Store Buffer),而不是直接写入Cache
- 只有更早请求执行的指令结果写入cache后,指令执行结果才写入Cache,通过对指令结果排序写入cache,使得执行看起来是有序的
指令乱序执行是结果,但原因并非只有CPU的乱序执行,而是由两种因素导致:
- 编译期:指令重排(编译器),编译器会为了性能而对指令重排,源码上先后的两行,被编译器编译后,可能调换指令顺序,但编译器会基于一套规则做指令重排,有明显依赖的指令不会被随意重排,指令重排不能破坏程序逻辑。
- 运行期:乱序执行(CPU),CPU的超标量流水线、以及预测执行、Cache-Miss等都有可能导致指令乱序执行,也就是说,后面的指令有可能先于前面的指令执行。
MESI
MESI(Modified / Exclusive / Shared / Invalid)是最基础、最经典、影响力最大的一类缓存一致性协议之一:
- 最早在 1980s 就已经提出并应用(如 Intel 80486)
- 奠定了基于嗅探(snooping)的写失效型缓存一致性协议的标准模型
- 后续主流 CPU(x86 / ARM / RISC-V)的缓存一致性机制,几乎全部是在 MESI 思想上演化而来(MESIF / MOESI / Directory-based MESI 等)
在现代 CPU 架构下,现代处理器引入了大量 MESI 诞生时并不存在的复杂性,纯 MESI 早已不再直接存在于工程实现中。
- 多核 / 多 Socket / NoC
- 乱序执行(OoO)
- 深度流水线与推测执行
- Store Buffer / Load Queue
- Invalidate Queue
- 非阻塞 Cache
- 弱内存模型
在教材和课程中,MESI 通常默认工作在一个极简处理器模型之上:
- In-order pipeline(顺序执行)
- 无 Store Buffer
- 无 Invalidate Queue
- 无乱序完成
- 无推测执行
- Cache 访问近似原子化
MESI 中对于每个 cacheline 规定了四种状态位
┌──────────────────────────────────────┐
│ Tag (地址标记) │ ← 物理地址高位
├──────────────────────────────────────┤
│ Coherence State │ ← M / E / S / I
├──────────────────────────────────────┤
│ Valid / Dirty / Permission / Lock 等 │
├──────────────────────────────────────┤
│ Replacement Metadata (LRU / PLRU …) │
├──────────────────────────────────────┤
│ Data Block (通常 64 Bytes) │ ← 实际缓存数据
└──────────────────────────────────────┘| 状态 | 含义 | 关键特征 |
|---|---|---|
| M Modified | 已修改 | 只存在于一个 cache,脏数据,内存过期 |
| E Exclusive | 独占未改 | 只存在于一个 cache,和内存一致 |
| S Shared | 共享 | 可存在多个 cache,和内存一致 |
| I Invalid | 无效 | 该行不可用 |
MESI 规定的总线事务
| 事务 | 含义 |
|---|---|
| BusRd | 读请求(我要读) |
| BusRdX | 读并准备写(我要改,别人失效) |
| BusUpgr | 升级为独占(已有共享 → 写) |
| Flush / WriteBack | 写回内存 |
举个例子:
Core0: r1 = x
Core1: r2 = x
Core0: x = 1
Core1: r3 = x| 时刻 | Core0 | Core1 | Memory |
|---|---|---|---|
| 初始 | I | I | 0 |
| r1=x | E | I | 0 |
| r2=x | S | S | 0 |
| x=1 | M | I | 0 |
| r3=x | S | S | 1 |
Store Buffer
考虑下面的代码:
void set_a() {
a = 1;
}- 假设运行在 core0 上的 set_a() 对整型变量 a 赋值 1,计算机通常不会直接写穿通到内存,而是会在 Cache 中修改对应 Cache Line
- 如果 Core0 的 Cache 里没有 a,赋值操作(store)会造成 Cache Miss
- Core0 会 stall 在等待 Cache 就绪(从内存加载变量 a 到对应的 Cache Line),但 Stall 会损害 CPU 性能,相当于 CPU 在这里停顿,白白浪费着宝贵的 CPU 时间
- 有了 Store Buffer,当变量在 Cache 中没有就位的时候,就先 Buffer 住这个 Store 操作,而Store 操作一旦进入 Store Buffer,core 便认为自己 Store 完成,当随后 Cache 就位,store 会自动写入对应 Cache。
所以,我们需要Store Buffer,每个Core都有独立的Store Buffer,每个Core都访问私有的Store Buffer,Store Buffer帮助CPU遮掩了Store操作带来的延迟。
当变量 a 所在的 Cache Line 终于从内存或其他核心传输到 Core0 的 Cache 时,硬件逻辑(通常是 Load/Store Unit, LSU)会自动执行以下操作:
- 信号触发:Cache 接收到了数据,通知 Store Buffer:“你要的那个地址
a已经就位了。” - 数据合并(Merge):Store Buffer 里的值(
1)会被覆盖到刚刚到达的那个 Cache Line 的对应位置。 - 状态更新:这个 Cache Line 的状态会被标记为 Modified(已修改),表示它是脏数据,之后需要同步回内存。
- 条目释放:Store Buffer 中关于
a = 1的记录被清除,腾出空间给下一个 Store 操作。
Store Buffer会带来什么问题?
a = 1;
b = 2;
assert(a == 1);上面的代码,断言 a=1 的时候,需要读变量 a 的值,而如果 a 在被赋值前就在 Cache 中,就会从Cache 中读到 a 的旧值,所以断言就可能失败。但这样的结果显然是不能接受的,它违背了最直观的程序顺序性。
变量 a 除了保存在内存外,还有两份拷贝:一份在 Store Buffer 里,一份在 Cache;如果不考虑这2份拷贝的关系,就会出现数据不一致。那怎么修复这个问题呢?
可以通过在 Core Load 数据的时候,先检查 Store Buffer 中是否有悬而未决的 a 的新值,如果有,则取新值;否则从 cache 取 a 的副本。这种技术在多级流水线 CPU 设计的时候就经常使用,叫 Store Forwarding。有了 Store Buffer Forwarding,就能确保单核程序的执行遵从程序顺序性。
可能有同学有疑问,为什么我写入 a=1 的时候要先读取 a 的值,这里是因为 Cache 并不是以“变量”为单位管理的,而是以 Cache Line(缓存行) 为单位的,通常一行是 64 字节。 假设变量
a所在的内存地址周围还有变量x,y,z: 如果你因为 Cache Miss 就直接在 Cache 里随便找个空位写下a = 1,那么这个 Cache Line 剩下的 60 个字节填什么? 如果你填 0,那就把原本内存里x,y,z的值给覆盖(破坏)掉了。 为了保证不破坏同一个缓存行内的其他数据,CPU 必须执行 Write-Allocate(写分配) 策略:先从内存里把整行(64字节)读进来,再把a = 1覆盖进去。
解决了单核的数据不一致问题,多核数据不一致的问题依旧存在,让我们考查下面的程序:
多核内存序问题
int a = 0; // 被CPU1 Cache
int b = 0; // 被CPU0 Cache
// CPU0执行
void x() {
a = 1;
b = 2;
}
// CPU1执行
void y() {
while (b == 0);
assert(a == 1);
}假设a和b都被初始化为0;CPU0执行x()函数,CPU1执行y()函数;变量a在CPU1的local Cache里,变量b在CPU0的local Cache里。
- CPU0 执行 a = 1 的时候,因为 a 不在 CPU0 的 local cache,CPU0 会把 a 的新值 1 写入 Store Buffer 里,并发送 Read Invalidate 消息给其他 CPU。
- CPU1 执行 while (b == 0),因为 b 不在 CPU1 的 local cache 里,CPU1 会发送 Read 消息去其他 CPU 获取 b 的值。
- CPU0 执行 b = 2,因为 b 在 CPU0 的 local Cache,所以直接更新 local cache 中 b 的副本。
- CPU0 收到 CPU1 发来的 read 消息,把 b 的新值 2 发送给 CPU1;同时存放 b 的 Cache Line 的状态被设置为 Shared,以反应 b 同时被 CPU0 和 CPU1 cache 住的事实。
- CPU1 收到 b 的新值 2 后结束循环,继续执行 assert(a == 1),因为此时 local Cache 中的 a 值为 0,所以断言失败。
- CPU1 收到 CPU0 发来的 Read Invalidate 后,更新 a 的值为 1,但为时已晚,程序在上一步已经崩了(assert 失败)。
Invalidate Queue
当一个变量加载到多个 core 的 Cache,则这个 Cache Line 处于 Shared 状态,如果 Core1 要修改这个变量,则需要通过发送核间消息 Invalidate 来通知其他 Core 把对应的 Cache Line 置为 Invalid,当其他 Core 都 Invalid 这个 CacheLine 后,则本 Core 获得该变量的独占权,这个时候就可以修改它了。
收到 Invalidate 消息的 core 需要回 Invalidate ACK,一个个 core 都这样 ACK,等所有 core 都回复完,Core1 才能修改它,这样 CPU 就白白浪费。
事实上,其他核在收到 Invalidate 消息后,会把 Invalidate 消息缓存到 Invalidate Queue,并立即回复 ACK,真正 Invalidate 动作可以延后再做,这样一方面因为 Core 可以快速返回别的 Core 发出的 Invalidate 请求,不会导致发生 Invalidate 请求的 Core 不必要的 Stall,另一方面也提供了进一步优化可能,比如在一个 CacheLine 里的多个变量的 Invalidate 可以攒一次做了。
但写 Store Buffer 的方式其实是 Write Invalidate,它并非立即写入内存,如果其他核此时从内存读数,则有可能不一致。
| 特性 | Store Buffer (存储缓冲) | Invalidate Queue (失效队列) |
|---|---|---|
| 所属方 | 发送方(正在执行 write 的核心) | 接收方(拥有该数据副本的核心) |
| 目的 | 为了不让 CPU 等待“获得所有权” | 为了不让 CPU 等待“实际删除缓存” |
| 核心逻辑 | “我先把要写的数存着,等拿到锁再发货。” | “我收到你的删除指令了,先记在小本子上,回个收到,等会再删。” |
| 副作用 | 本地写、别人看不见(自说自话) | 别人改了、我还在读旧的(后知后觉) |
内存屏障
那有没有方法确保对 a 的赋值一定先于对 b 的赋值呢?有,内存屏障被用来提供这个保障。
内存屏障(Memory Barrier),也称内存栅栏、屏障指令等,是一类同步屏障指令,是 CPU 或编译器在对内存随机访问的操作中的一个同步点,同步点之前的所有读写操作都执行后,才可以开始执行此点之后的操作。语义上,内存屏障之前的所有写操作都要写入内存;内存屏障之后的读操作都可以获得同步屏障之前的写操作的结果。
wmb()(Write Memory Barrier):仅影响写操作。保证屏障前的写指令一定比屏障后的写指令先被别人看到。rmb()(Read Memory Barrier):仅影响读操作。保证屏障前的读指令一定比屏障后的读指令先完成。mb()(Full Memory Barrier):全能屏障,同时具备读写屏障的功能。smp_前缀:这是一个编译优化。如果你的系统是单核的,smp_mb()会退化成一个简单的编译器屏障(防止编译器乱序);如果是多核系统,它才会变成真正的硬件指令(如 x86 的mfence)。
内存屏障,其实就是提供一种机制,确保代码里顺序写下的多行,会按照书写的顺序,被存入内存,主要是解决 Store Buffer 引入导致的写入内存间隙的问题。
void x() {
a = 1;
wmb();
b = 2;
}像上面那样在 a=1 和 b=2 之间插入一条内存屏障语句,就能确保 a=1 先于 b=2 生效,从而解决了内存乱序访问问题,那插入的这句 smp_mb(),到底会干什么呢?
回忆前面的流程,CPU0 在执行完 a = 1 之后,执行 smp_mb()操作,这时候,它会给 Store Buffer 里的所有数据项做一个标记(marked),然后继续执行 b = 2,但这时候虽然 b 在自己的 cache 里,但由于 store buffer 里有 marked 条目,所以,CPU0 不会修改 cache 中的 b,而是把它写入 Store Buffer;所以 CPU0 收到 Read 消息后,会把 b 的 0 值发给 CPU1,所以继续在 while (b)自旋。
简而言之,Core 执行到 write memory barrier(wmb)的时候,如果 Store Buffer 还有悬而未决的 store 操作,则都会被 mark 上,直到被标注的 Store 操作进入内存后,后续的 Store 操作才能被执行,因此 wmb 保障了 barrier 前后操作的顺序,它不关心 barrier 前的多个操作的内存序,以及 barrier 后的多个操作的内存序,是否与 Global Memory Order 一致。
a = 1;
b = 2;
wmb();
c = 3;
d = 4;wmb()保证“a=1;b=2”发生在“c=3;d = 4”之前,不保证 a = 1 和 b = 2 的内存序,也不保证 c = 3 和 d = 4 的内部序。
Invalidate Queue的引入的问题
就像引入 Store Buffer 会影响 Store 的内存一致性,Invalidate Queue 的引入会影响 Load 的内存一致性。因为 Invalidate queue 会缓存其他核发过来的消息,比如 Invalidate 某个数据的消息被 delay 处置,导致 core 在 Cache Line 中命中这个数据,而这个 Cache Line 本应该被 Invalidate 消息标记无效。如何解决这个问题呢?
- 一种思路是硬件确保每次 load 数据的时候,需要确保 Invalidate Queue 被清空,这样可以保证 load 操作的强顺序。
- 软件的思路,就是仿照 wmb()的定义,加入 rmb()约束。rmb()给我们的 invalidate queue 加上标记。当一个 load 操作发生的时候,之前的 rmb()所有标记的 invalidate 命令必须全部执行完成,然后才可以让随后的 load 发生。这样,我们就在 rmb()前后保证了 load 观察到的顺序等同于 global memory order。
所以,我们可以像下面这样修改代码:
a = 1;
wmb();
b = 2;
while(b != 2) {};
rmb();
assert(a == 1);- 为了提高处理器的性能,SMP 中引入了 store buffer(以及对应实现 store buffer forwarding)和 invalidate queue。
- store buffer 的引入导致 core 上的 store 顺序可能不匹配于 global memory 的顺序,对此,我们需要使用 wmb()来解决。
- invalidate queue 的存在导致 core 上观察到的 load 顺序可能与 global memory order 不一致,对此,我们需要使用 rmb()来解决。
- 由于 wmb()和 rmb()分别只单独作用于 store buffer 和 invalidate queue,因此这两个 memory barrier 共同保证了 store/load 的顺序。
伪共享
多个线程同时读写同一个 Cache Line 中的变量、导致 CPU Cache 频繁失效,从而使得程序性能下降的现象称为伪共享(False Sharing)。
const size_t shm_size = 16*1024*1024;
static char shm[shm_size];
std::atomic<size_t> shm_offset{0};
void f() {
for (;;) {
auto off = shm_offset.fetch_add(sizeof(long));
if (off >= shm_size) break;
*(long*)(shm + off) = off;
}
}考察上面的程序:shm 是一块 16M 字节的内存,f()函数的循环里,视 shm 为 long 类型的数组,依次给每个元素赋值,shm_offset 用于记录偏移位置,shm_offset.fetch_add(sizeof(long))原子性的增加 shm_offset 的值(因为 x86_64 系统上 long 的长度为 8,所以 shm_offset 每次增加 8),并返回增加前的值,对 shm 上 long 数组的每个元素赋值后,结束循环从函数返回。
因为 shm_offset 是 atomic 类型变量,所以多线程调用 f()依然能正常工作,虽然多个线程会竞争 shm_offset,但每个线程会排他性的对各 long 元素赋值,多线程并行会加快对 shm 的赋值操作。我们加上多线程调用代码:
std::atomic<size_t> step{0};
const int THREAD_NUM = 2;
void work_thread() {
const int LOOP_N = 10;
for (int n = 1; n <= LOOP_N; ++n) {
f();
++step;
while (step.load() < n * THREAD_NUM) {}
shm_offset = 0;
}
}
int main() {
std::thread threads[THREAD_NUM];
for (int i = 0; i < THREAD_NUM; ++i) {
threads[i] = std::move(std::thread(work_thread));
}
for (int i = 0; i < THREAD_NUM; ++i) {
threads[i].join();
}
return 0;
}- main 函数里启动 2 个工作线程 work_thread。
- 工作线程对 shm 共计赋值 10 轮,后面的每一轮会访问 Cache 里的 shm 数据,step 用于 work_thread 之间每一轮的同步。
- 工作线程调用完 f()后会增加 step,等 2 个工作线程都调用完之后,step 的值增加到 n * THREAD_NUM 后,while()会结束循环,重置 shm_offset,重新开始新一轮对 shm 的赋值。
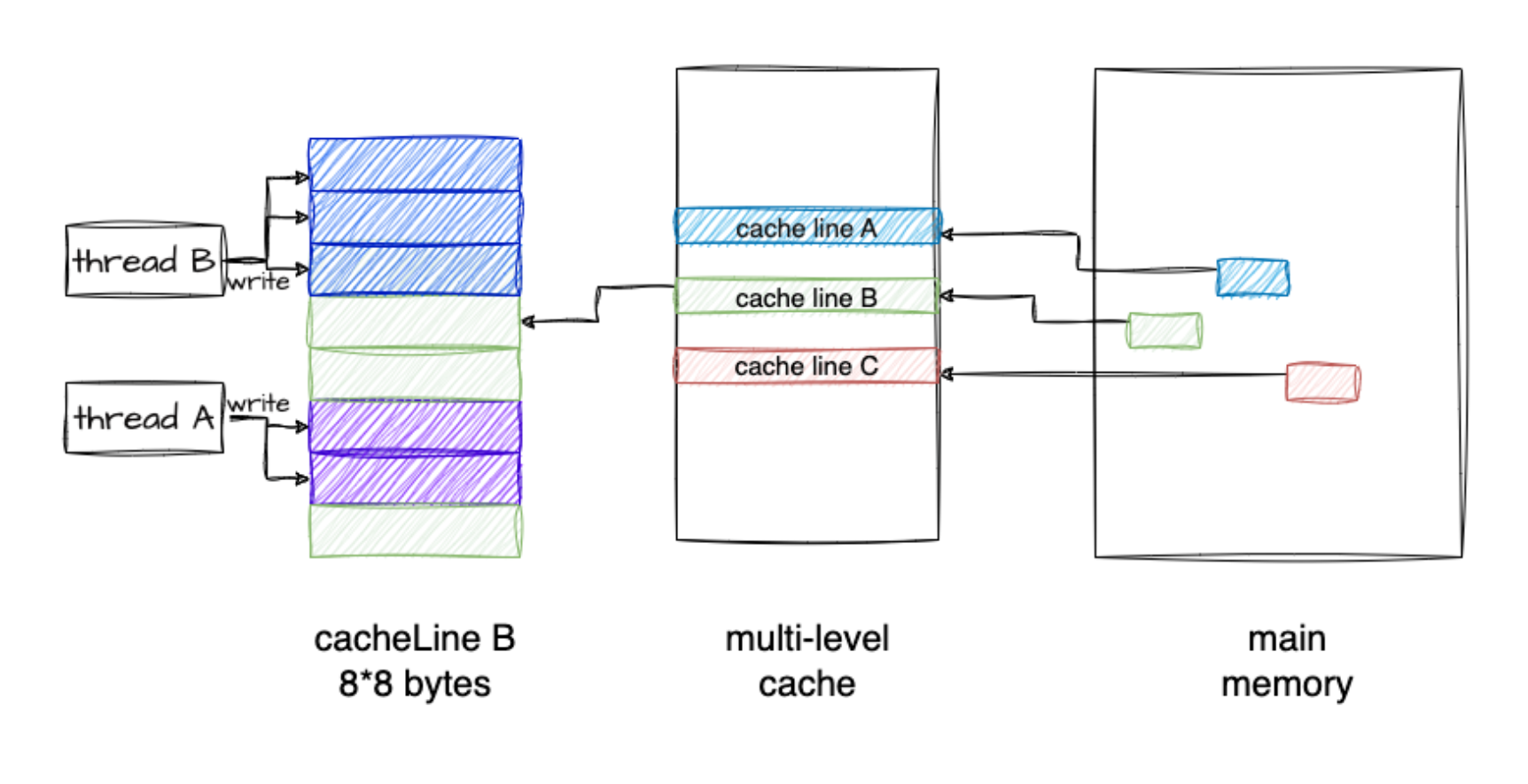
编译后执行上面的程序,产生如下的结果:
real 0m3.406s
user 0m6.740s
sys 0m0.040s
real列显式耗时3.4秒。
改进版f_fast
我们稍微修改一下 f(),改进版f函数取名 f_fast:
const size_t shm_size = 16*1024*1024;
static char shm[shm_size];
std::atomic<size_t> shm_offset{0};
void f() {
for (;;) {
auto off = shm_offset.fetch_add(sizeof(long));
if (off >= shm_size) break;
*(long*)(shm + off) = off;
}
}
void f_fast() {
for (;;) {
const long inner_loop = 16;
auto off = shm_offset.fetch_add(sizeof(long) * inner_loop);
for (long j = 0; j < inner_loop; ++j) {
if (off >= shm_size) return;
*(long*)(shm + off) = j;
off += sizeof(long);
}
}
}for 循环里,shm_offset 不再是每次增加 8 字节(sizeof(long)),而是 8*16=128 字节,然后在内层的循环里,依次对 16 个 long 连续元素赋值,然后下一轮循环又再次增加 128 字节,直到完成对 shm 的赋值。如图所示:
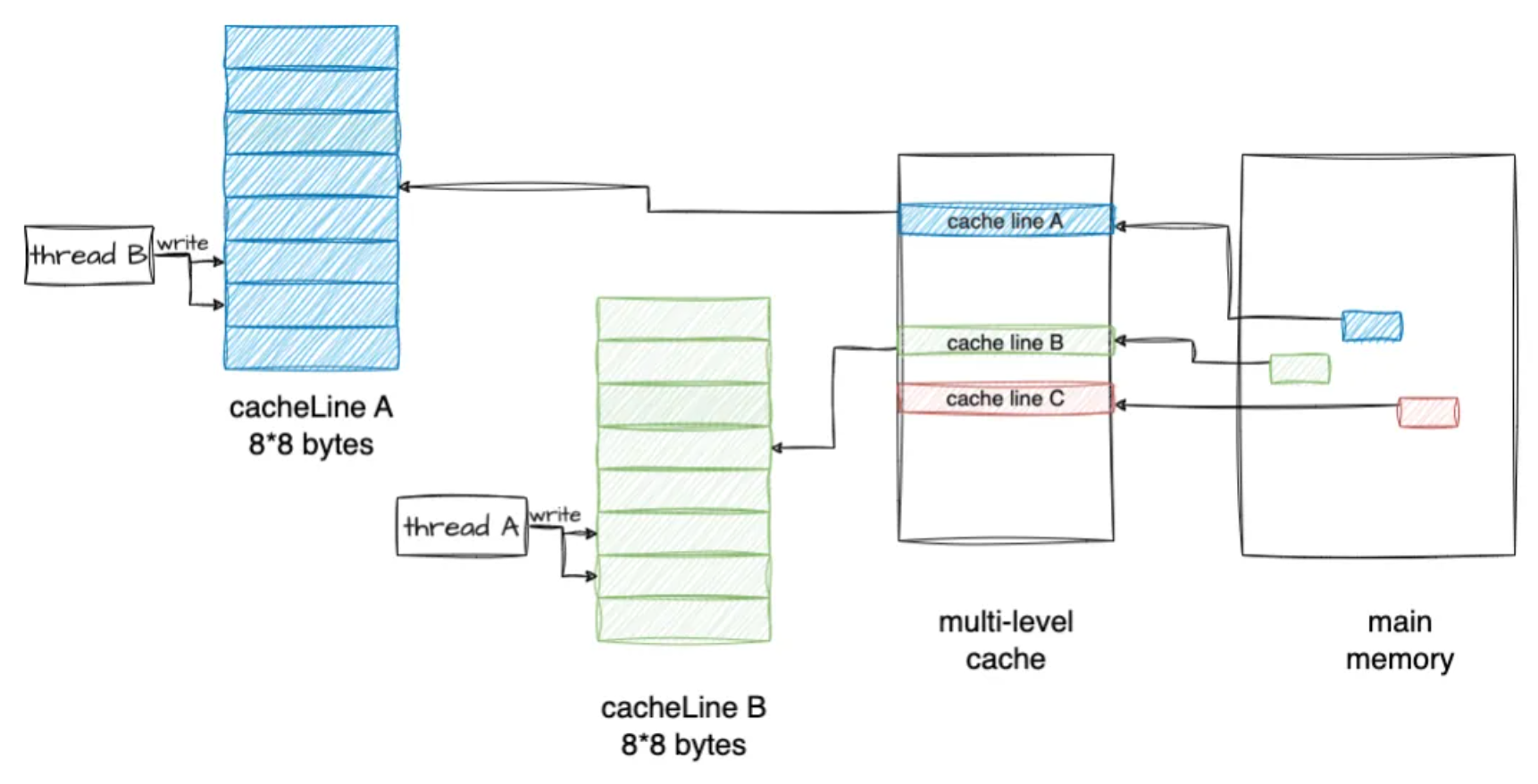
编译后重新执行程序,结果显示耗时降低到0.06秒,对比前一种耗时3.4秒,f_fast性能提升明显。
real 0m0.062s
user 0m0.110s
sys 0m0.012s
f 和 f_fast 的行为差异
shm 数组总共有 2M 个 long 元素,因为 16M / sizeof(long) 得 2M:
1、f()函数行为逻辑
- 线程 1 和线程 2 的 work_thread 里会交错地对 shm 元素赋值,shm 的 2M 个 long 元素,会顺序的一个接一个的派给 2 个线程去赋值。
- 可能的行为:元素 1 由线程 1 赋值,元素 2 由线程 2 赋值,然后元素 3 和元素 4 由线程 1 赋值,然后元素 5 又由线程 2 赋值...
- 每次分派元素的时候,shm_offset 都会 atomic 的增加 8 字节,所以不会出现 2 个线程给同 1 个元素赋值的情况。
2、f_fast()函数行为逻辑
- 每次派元素的时候,shm_offset 原子性的增加 128 字节(16 个元素)。
- 这 16 个字节作为一个整体,派给线程 1 或者线程 2;虽然线程 1 和线程 2 还是会交错的操作 shm 元素,但是以 16 个元素(128 字节)为单元,这 16 个连续的元素不会被分开派发给不同线程。
- 一次派发的 16 个元素,会在一个线程里被一个接着一个的赋值(内部循环里)。
为什么f_fast更快
第一眼感觉是 f_fast()里 shm_offset.fetch_add()调用频次降低到了原来的 1/16,有理由怀疑是原子变量的竞争减少导致程序执行速度加快。为了验证,让我们在内层的循环里加一个原子变量 test 的 fetch_add,test 原子变量的竞争会像 f()函数里 shm_offset.fetch_add()一样激烈,修改后的 f_fast 代码变成下面这样:
void f_fast() {
for (;;) {
const long inner_loop = 16;
auto off = shm_offset.fetch_add(sizeof(long) * inner_loop);
for (long j = 0; j < inner_loop; ++j) {
test.fetch_add(1);
if (off >= shm_size) return;
*(long*)(shm + off) = j;
off += sizeof(long);
}
}
}为了避免 test.fetch_add(1)的调用被编译器优化掉,我们在 main 函数的最后把 test 的值打印出来。编译后测试一下,结果显示:执行时间只是稍微增加到 real 0m0.326s,很显然,并不是 atomic 的调用频次减少导致性能飙升。
重新审视 f()循环里的逻辑:f()循环里的操作很简单:原子增加、判断、赋值。我们把 f()的里赋值注释掉,再测试一下,发现它的速度得到了很大提升,看来是*(long*)(shm + off) = off 这一行代码执行慢,但这明明只是一行赋值。我们把它反汇编来看,它只是一个 mov 指令,源操作数是寄存器,目标操作数是内存地址,从寄存器拷贝数据到一个内存地址,为什么会这么慢呢?
原因
现代 CPU 可以有多个核,每个核有自己的 L1-L2 缓存,L1 又区分数据缓存(L1-DCache)和指令缓存(L1-ICache),L2 不区分数据和指令 Cache,而 L3 是跨核共享的,L3 通过内存总线连接到内存,内存被所有 CPU 所有 Core 共享。
CPU 访问 L1 Cache 的速度大约是访问内存的 100 倍,Cache 作为 CPU 与内存之间的缓存,减少对内存的访问频率。
从内存加载数据到 Cache 的时候,是以 Cache Line 为长度单位的,Cache Line 的长度通常是 64 字节,所以,那怕只读一个字节,但是包含该字节的整个 Cache Line 都会被加载到缓存,同样,如果修改一个字节,那么最终也会导致整个 Cache Line 被冲刷到内存。
如果一块内存数据被多个线程访问,假设多个线程在多个 Core 上并行执行,那么它便会被加载到多个 Core 的的 Local Cache 中;这些线程在哪个 Core 上运行,就会被加载到哪个 Core 的 Local Cache 中,所以,内存中的一个数据,在不同 Core 的 Cache 里会同时存在多份拷贝。
那么,便会存在缓存一致性问题。当一个 Core 修改其缓存中的值时,其他 Core 不能再使用旧值。该内存位置将在所有缓存中失效。此外,由于缓存以缓存行而不是单个字节的粒度运行,因此整个缓存行将在所有缓存中失效。如果我们修改了 Core1 缓存里的某个数据,则该数据所在的 Cache Line 的状态需要同步给其他 Core 的缓存,Core 之间可以通过核间消息同步状态,比如通过发送 Invalidate 消息给其他核,接收到该消息的核会把对应 Cache Line 置为无效,然后重新从内存里加载最新数据。
当然,被加载到多个 Core 缓存中的同一 Cache Line,会被标记为共享(Shared)状态,对共享状态的缓存行进行修改,需要先获取缓存行的修改权(独占),MESI 协议用来保证多核缓存的一致性,更多的细节可以参考 MESI 的文章。
示例分析
假设线程 1 运行在 Core1,线程 2 运行在 Core2。
- 因为 shm 被线程 1 和线程 2 这两个线程并发访问,所以 shm 的内存数据会以 Cache Line 粒度,被同时加载到 2 个 Core 的 Cache,因为被多核共享,所以该 Cache Line 被标注为 Shared 状态。
- 假设线程 1 在 offset 为 64 的位置写入了一个 8 字节的数据(sizeof(long)),要修改一个状态为 Shared 的 Cache Line,Core1 会发送核间通信消息到 Core2,去拿到该 Cache Line 的独占权,在这之后,Core1 才能修改 Local Cache。
- 线程 1 执行完 shm_offset.fetch_add(sizeof(long))后,shm_offset 会增加到 72。
- 这时候 Core2 上运行的线程 2 也会执行 shm_offset.fetch_add(sizeof(long)),它返回 72 并将 shm_offset 增加到 80。
- 线程 2 接下来要修改 shm[72]的内存位置,因为 shm[64]和 shm[72]在一个 Cache Line,而这个 Cache Line 又被置为 Invalidate,所以,它需要从内存里重新加载这一个 Cache Line,而在这之前,Core1 上的线程 1 需要把 Cache Line 冲刷到内存,这样线程 2 才能加载最新的数据。
这种交替执行模式,相当于 Core1 和 Core2 之间需要频繁的发送核间消息,收到消息的 Core 的 Cache Line 被置为无效,并重新从内存里加载数据到 Cache,每次修改后都需要把 Cache 中的数据刷入内存,这相当于废弃掉了 Cache,因为每次读写都直接跟内存打交道,Cache 的作用不复存在,这就是性能低下的原因。
这种多核多线程程序,因为并发读写同一个 Cache Line 的数据(临近位置的内存数据),导致 Cache Line 的频繁失效,内存的频繁 Load/Store,从而导致性能急剧下降的现象叫伪共享,伪共享是性能杀手。
另一个伪共享的例子
假设线程 x 和 y,分别修改 Data 的 a 和 b 变量,如果被频繁调用,也会出现性能低下的情况,怎么规避呢?
struct Data {
int a;
int b;
} data; // global
void thread1() {
data.a = 1;
}
void thread2() {
data.b = 2;
}空间换时间
避免 Cache 伪共享导致性能下降的思路是用空间换时间,通过增加填充,让 a 和 b 两个变量分布到不同的 Cache Line,这样对 a 和 b 的修改就会作用于不同 Cache Line,就能避免 Cache 失效的问题。
struct Data {
int a;
int padding[60];
int b;
};在 Linux kernel 中存在__cacheline_aligned_in_smp 宏定义用于解决 false sharing 问题。
#ifdef CONFIG_SMP
#define __cacheline_aligned_in_smp __cacheline_aligned
#else
#define __cacheline_aligned_in_smp
#endif
struct Data {
int a;
int b __cacheline_aligned_in_smp;
};从上面的宏定义,可以看到:
- 在多核系统里,该宏定义是 __cacheline_aligned,也就是 Cache Line 的大小。
- 在单核系统里,该宏定义是空的。
pthread 接口提供的几种同步原语如下:
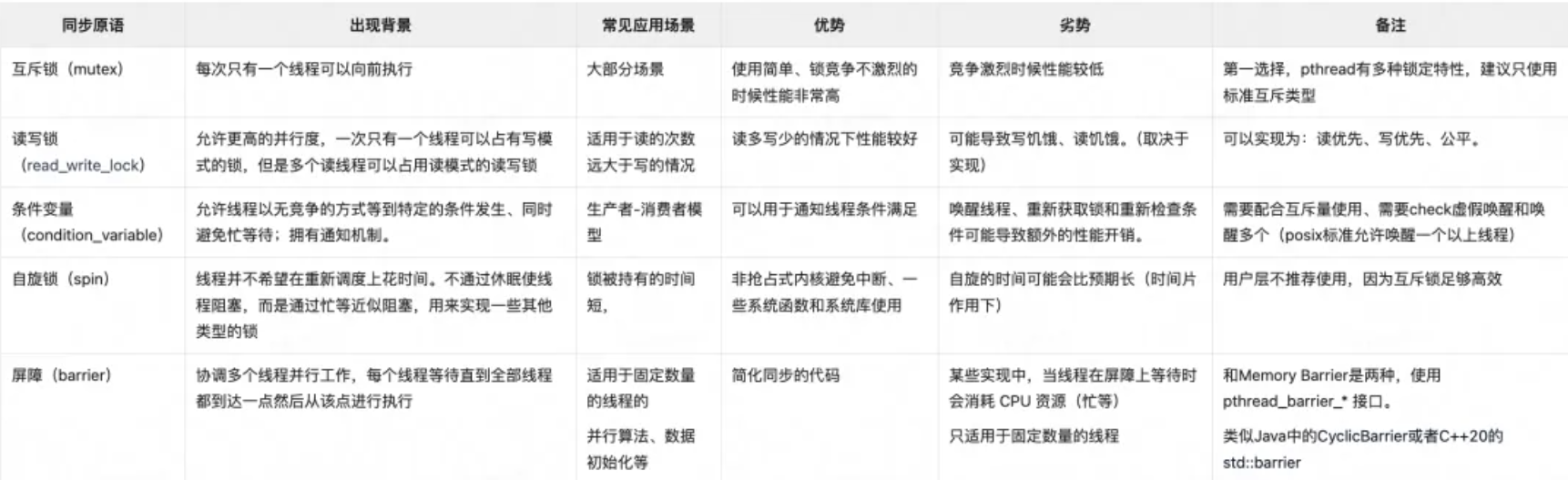
由于 linux 下线程和进程本质都是 LWP,那么进程间通信使用的 IPC(管道、FIFO、消息队列、信号量)线程间也可以使用,也可以达到相同的作用。但是由于 IPC 资源在进程退出时不会清理(因为它是系统资源),因此不建议使用。
以下是一些非锁但是也能实现线程安全或者部分线程安全的常见做法:
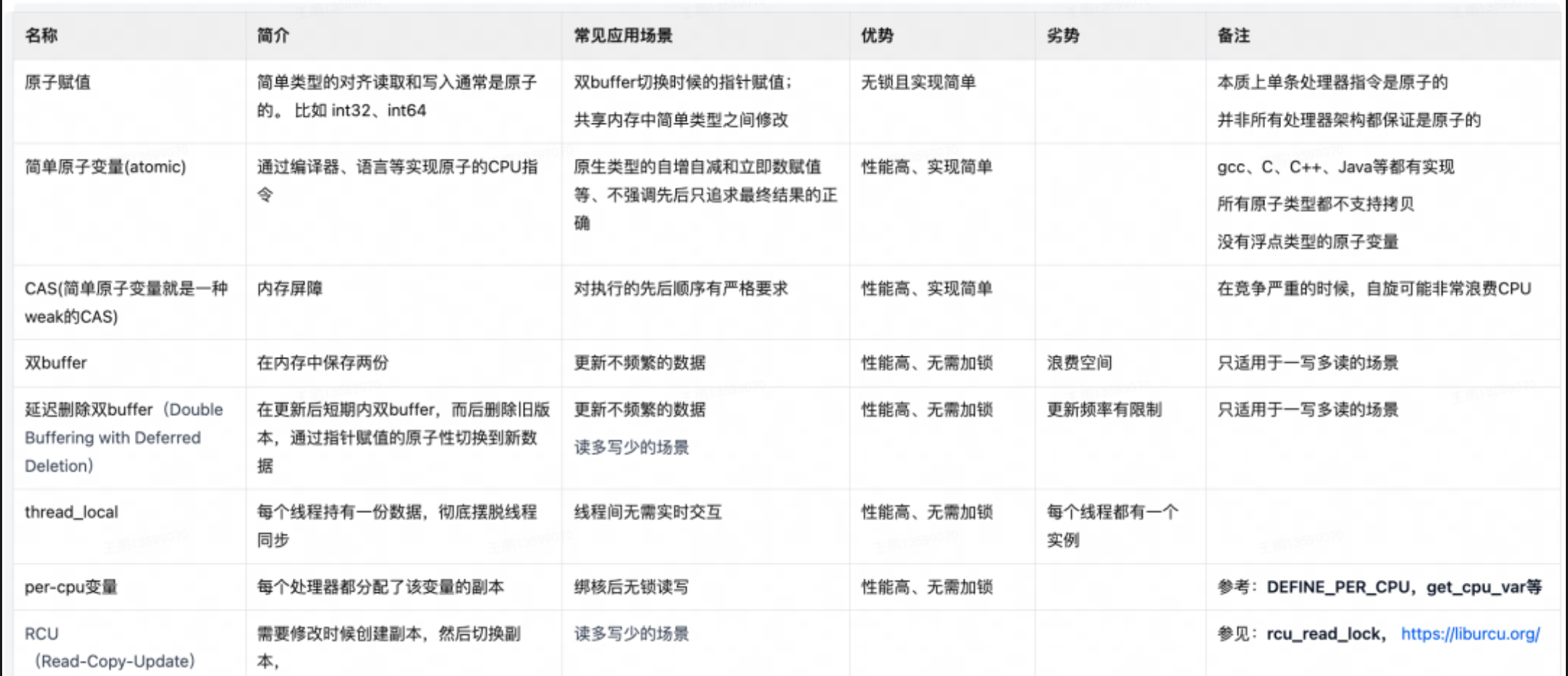
可以看到,上面很多做法都是采用了副本,尽量避免在 thread 中间共享数据。最快的同步就是没同步(The fastest synchronization of all is the kind that never takes place),Share nothing is best。
reference: 美团技术团队:基本功 | 一文讲清多线程和多线程同步
 YJ
YJ